
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Como siempre, el código de este ejemplo utilizará la API tf.keras , sobre la que puede obtener más información en la guía de TensorFlow Keras .
En los dos ejemplos anteriores ( clasificación de texto y predicción de la eficiencia del combustible ), vimos que la precisión de nuestro modelo en los datos de validación alcanzaría su punto máximo después del entrenamiento durante una serie de épocas y luego se estancaría o comenzaría a disminuir.
En otras palabras, nuestro modelo se sobreajustaría a los datos de entrenamiento. Es importante aprender a lidiar con el sobreajuste. Aunque a menudo es posible lograr una alta precisión en el conjunto de entrenamiento , lo que realmente queremos es desarrollar modelos que generalicen bien a un conjunto de prueba (o datos que no han visto antes).
Lo contrario de overfitting es underfitting . El desajuste ocurre cuando todavía hay espacio para mejorar los datos del tren. Esto puede suceder por varias razones: si el modelo no es lo suficientemente poderoso, está demasiado regularizado o simplemente no se ha entrenado lo suficiente. Esto significa que la red no ha aprendido los patrones relevantes en los datos de entrenamiento.
Sin embargo, si entrena durante demasiado tiempo, el modelo comenzará a sobreajustarse y aprenderá patrones de los datos de entrenamiento que no se generalizan a los datos de prueba. Tenemos que lograr un equilibrio. Comprender cómo entrenar para un número apropiado de épocas, como exploraremos a continuación, es una habilidad útil.
Para evitar el sobreajuste, la mejor solución es utilizar datos de entrenamiento más completos. El conjunto de datos debe cubrir la gama completa de entradas que se espera que maneje el modelo. Los datos adicionales solo pueden ser útiles si cubren casos nuevos e interesantes.
Un modelo entrenado con datos más completos, naturalmente, generalizará mejor. Cuando eso ya no es posible, la siguiente mejor solución es utilizar técnicas como la regularización. Estos imponen restricciones sobre la cantidad y el tipo de información que su modelo puede almacenar. Si una red solo puede darse el lujo de memorizar una pequeña cantidad de patrones, el proceso de optimización la obligará a centrarse en los patrones más destacados, que tienen más posibilidades de generalizarse bien.
En este cuaderno, exploraremos varias técnicas de regularización comunes y las usaremos para mejorar un modelo de clasificación.
Configuración
Antes de comenzar, importe los paquetes necesarios:
import tensorflow as tf
from tensorflow.keras import layers
from tensorflow.keras import regularizers
print(tf.__version__)
2.8.0-rc1
!pip install git+https://github.com/tensorflow/docs
import tensorflow_docs as tfdocs
import tensorflow_docs.modeling
import tensorflow_docs.plots
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import pathlib
import shutil
import tempfile
logdir = pathlib.Path(tempfile.mkdtemp())/"tensorboard_logs"
shutil.rmtree(logdir, ignore_errors=True)
El conjunto de datos de Higgs
El objetivo de este tutorial no es hacer física de partículas, así que no se detenga en los detalles del conjunto de datos. Contiene 11 000 000 ejemplos, cada uno con 28 funciones y una etiqueta de clase binaria.
gz = tf.keras.utils.get_file('HIGGS.csv.gz', 'http://mlphysics.ics.uci.edu/data/higgs/HIGGS.csv.gz')
Downloading data from http://mlphysics.ics.uci.edu/data/higgs/HIGGS.csv.gz 2816409600/2816407858 [==============================] - 123s 0us/step 2816417792/2816407858 [==============================] - 123s 0us/step
FEATURES = 28
La clase tf.data.experimental.CsvDataset se puede usar para leer registros csv directamente desde un archivo gzip sin un paso de descompresión intermedio.
ds = tf.data.experimental.CsvDataset(gz,[float(),]*(FEATURES+1), compression_type="GZIP")
Esa clase de lector csv devuelve una lista de escalares para cada registro. La siguiente función vuelve a empaquetar esa lista de escalares en un par (feature_vector, label).
def pack_row(*row):
label = row[0]
features = tf.stack(row[1:],1)
return features, label
TensorFlow es más eficiente cuando opera con grandes lotes de datos.
Entonces, en lugar de volver a empaquetar cada fila individualmente, cree un nuevo conjunto de Dataset que tome lotes de 10000 ejemplos, aplique la función pack_row a cada lote y luego divida los lotes en registros individuales:
packed_ds = ds.batch(10000).map(pack_row).unbatch()
Echa un vistazo a algunos de los registros de este nuevo packed_ds .
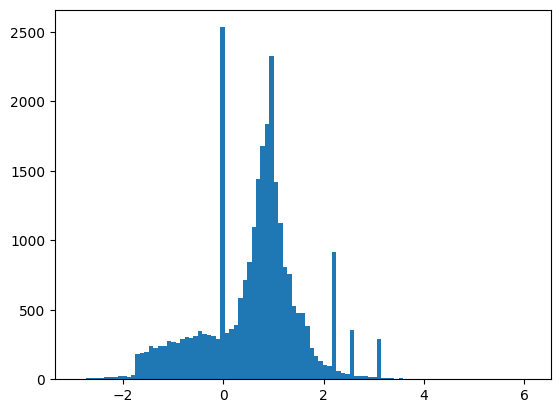
Las características no están perfectamente normalizadas, pero esto es suficiente para este tutorial.
for features,label in packed_ds.batch(1000).take(1):
print(features[0])
plt.hist(features.numpy().flatten(), bins = 101)
tf.Tensor( [ 0.8692932 -0.6350818 0.22569026 0.32747006 -0.6899932 0.75420225 -0.24857314 -1.0920639 0. 1.3749921 -0.6536742 0.9303491 1.1074361 1.1389043 -1.5781983 -1.0469854 0. 0.65792954 -0.01045457 -0.04576717 3.1019614 1.35376 0.9795631 0.97807616 0.92000484 0.72165745 0.98875093 0.87667835], shape=(28,), dtype=float32)
Para mantener este tutorial relativamente corto, use solo las primeras 1000 muestras para validación y las siguientes 10 000 para entrenamiento:
N_VALIDATION = int(1e3)
N_TRAIN = int(1e4)
BUFFER_SIZE = int(1e4)
BATCH_SIZE = 500
STEPS_PER_EPOCH = N_TRAIN//BATCH_SIZE
Los métodos Dataset.skip y Dataset.take facilitan esta tarea.
Al mismo tiempo, use el método Dataset.cache para asegurarse de que el cargador no necesite volver a leer los datos del archivo en cada época:
validate_ds = packed_ds.take(N_VALIDATION).cache()
train_ds = packed_ds.skip(N_VALIDATION).take(N_TRAIN).cache()
train_ds
<CacheDataset element_spec=(TensorSpec(shape=(28,), dtype=tf.float32, name=None), TensorSpec(shape=(), dtype=tf.float32, name=None))>
Estos conjuntos de datos devuelven ejemplos individuales. Utilice el método .batch para crear lotes de un tamaño adecuado para el entrenamiento. Antes de agrupar también recuerde .shuffle y .repeat el conjunto de entrenamiento.
validate_ds = validate_ds.batch(BATCH_SIZE)
train_ds = train_ds.shuffle(BUFFER_SIZE).repeat().batch(BATCH_SIZE)
Demostrar sobreajuste
La forma más sencilla de evitar el sobreajuste es comenzar con un modelo pequeño: un modelo con una pequeña cantidad de parámetros que se pueden aprender (determinado por la cantidad de capas y la cantidad de unidades por capa). En el aprendizaje profundo, la cantidad de parámetros que se pueden aprender en un modelo a menudo se denomina "capacidad" del modelo.
Intuitivamente, un modelo con más parámetros tendrá más "capacidad de memorización" y, por lo tanto, podrá aprender fácilmente un mapeo perfecto tipo diccionario entre las muestras de entrenamiento y sus objetivos, un mapeo sin ningún poder de generalización, pero esto sería inútil al hacer predicciones. en datos nunca antes vistos.
Siempre tenga esto en cuenta: los modelos de aprendizaje profundo tienden a adaptarse bien a los datos de entrenamiento, pero el verdadero desafío es la generalización, no la adaptación.
Por otro lado, si la red tiene recursos de memorización limitados, no podrá aprender el mapeo tan fácilmente. Para minimizar su pérdida, tendrá que aprender representaciones comprimidas que tengan más poder predictivo. Al mismo tiempo, si hace que su modelo sea demasiado pequeño, tendrá dificultades para adaptarse a los datos de entrenamiento. Existe un equilibrio entre "demasiada capacidad" y "insuficiente capacidad".
Desafortunadamente, no existe una fórmula mágica para determinar el tamaño o la arquitectura correctos de su modelo (en términos de la cantidad de capas o el tamaño correcto para cada capa). Tendrás que experimentar usando una serie de arquitecturas diferentes.
Para encontrar un tamaño de modelo apropiado, es mejor comenzar con relativamente pocas capas y parámetros, luego comenzar a aumentar el tamaño de las capas o agregar nuevas capas hasta que vea rendimientos decrecientes en la pérdida de validación.
Comience con un modelo simple usando solo layers.Dense como línea de base, luego cree versiones más grandes y compárelas.
Procedimiento de entrenamiento
Muchos modelos entrenan mejor si reduce gradualmente la tasa de aprendizaje durante el entrenamiento. Use optimizers.schedules para reducir la tasa de aprendizaje con el tiempo:
lr_schedule = tf.keras.optimizers.schedules.InverseTimeDecay(
0.001,
decay_steps=STEPS_PER_EPOCH*1000,
decay_rate=1,
staircase=False)
def get_optimizer():
return tf.keras.optimizers.Adam(lr_schedule)
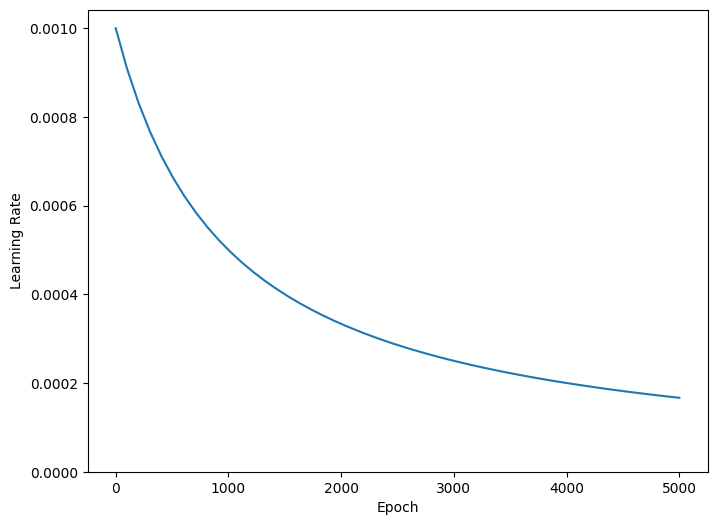
El código anterior establece una schedules.InverseTimeDecay para disminuir hiperbólicamente la tasa de aprendizaje a la mitad de la tasa base en 1000 épocas, 1/3 en 2000 épocas y así sucesivamente.
step = np.linspace(0,100000)
lr = lr_schedule(step)
plt.figure(figsize = (8,6))
plt.plot(step/STEPS_PER_EPOCH, lr)
plt.ylim([0,max(plt.ylim())])
plt.xlabel('Epoch')
_ = plt.ylabel('Learning Rate')
Cada modelo en este tutorial usará la misma configuración de entrenamiento. Así que configúrelos de manera reutilizable, comenzando con la lista de devoluciones de llamada.
El entrenamiento para este tutorial se ejecuta durante muchas épocas cortas. Para reducir el ruido de registro, use tfdocs.EpochDots que simplemente imprime un archivo . para cada época y un conjunto completo de métricas cada 100 épocas.
A continuación, incluya las callbacks.EarlyStopping de llamada. EarlyStopping para evitar tiempos de entrenamiento largos e innecesarios. Tenga en cuenta que esta devolución de llamada está configurada para monitorear val_binary_crossentropy , no val_loss . Esta diferencia será importante más adelante.
Usa callbacks.TensorBoard para generar registros de TensorBoard para el entrenamiento.
def get_callbacks(name):
return [
tfdocs.modeling.EpochDots(),
tf.keras.callbacks.EarlyStopping(monitor='val_binary_crossentropy', patience=200),
tf.keras.callbacks.TensorBoard(logdir/name),
]
De manera similar, cada modelo utilizará la misma configuración de Model.compile y Model.fit :
def compile_and_fit(model, name, optimizer=None, max_epochs=10000):
if optimizer is None:
optimizer = get_optimizer()
model.compile(optimizer=optimizer,
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=[
tf.keras.losses.BinaryCrossentropy(
from_logits=True, name='binary_crossentropy'),
'accuracy'])
model.summary()
history = model.fit(
train_ds,
steps_per_epoch = STEPS_PER_EPOCH,
epochs=max_epochs,
validation_data=validate_ds,
callbacks=get_callbacks(name),
verbose=0)
return history
modelo diminuto
Comience entrenando un modelo:
tiny_model = tf.keras.Sequential([
layers.Dense(16, activation='elu', input_shape=(FEATURES,)),
layers.Dense(1)
])
size_histories = {}
size_histories['Tiny'] = compile_and_fit(tiny_model, 'sizes/Tiny')
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 16) 464
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 481
Trainable params: 481
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.4961, binary_crossentropy:0.7294, loss:0.7294, val_accuracy:0.4840, val_binary_crossentropy:0.7200, val_loss:0.7200,
....................................................................................................
Epoch: 100, accuracy:0.5931, binary_crossentropy:0.6279, loss:0.6279, val_accuracy:0.5860, val_binary_crossentropy:0.6288, val_loss:0.6288,
....................................................................................................
Epoch: 200, accuracy:0.6157, binary_crossentropy:0.6178, loss:0.6178, val_accuracy:0.6200, val_binary_crossentropy:0.6134, val_loss:0.6134,
....................................................................................................
Epoch: 300, accuracy:0.6370, binary_crossentropy:0.6086, loss:0.6086, val_accuracy:0.6220, val_binary_crossentropy:0.6055, val_loss:0.6055,
....................................................................................................
Epoch: 400, accuracy:0.6522, binary_crossentropy:0.6008, loss:0.6008, val_accuracy:0.6260, val_binary_crossentropy:0.5997, val_loss:0.5997,
....................................................................................................
Epoch: 500, accuracy:0.6513, binary_crossentropy:0.5946, loss:0.5946, val_accuracy:0.6480, val_binary_crossentropy:0.5911, val_loss:0.5911,
....................................................................................................
Epoch: 600, accuracy:0.6636, binary_crossentropy:0.5894, loss:0.5894, val_accuracy:0.6390, val_binary_crossentropy:0.5898, val_loss:0.5898,
....................................................................................................
Epoch: 700, accuracy:0.6696, binary_crossentropy:0.5852, loss:0.5852, val_accuracy:0.6530, val_binary_crossentropy:0.5870, val_loss:0.5870,
....................................................................................................
Epoch: 800, accuracy:0.6706, binary_crossentropy:0.5824, loss:0.5824, val_accuracy:0.6590, val_binary_crossentropy:0.5850, val_loss:0.5850,
....................................................................................................
Epoch: 900, accuracy:0.6709, binary_crossentropy:0.5796, loss:0.5796, val_accuracy:0.6680, val_binary_crossentropy:0.5831, val_loss:0.5831,
....................................................................................................
Epoch: 1000, accuracy:0.6780, binary_crossentropy:0.5769, loss:0.5769, val_accuracy:0.6530, val_binary_crossentropy:0.5851, val_loss:0.5851,
....................................................................................................
Epoch: 1100, accuracy:0.6735, binary_crossentropy:0.5752, loss:0.5752, val_accuracy:0.6620, val_binary_crossentropy:0.5807, val_loss:0.5807,
....................................................................................................
Epoch: 1200, accuracy:0.6759, binary_crossentropy:0.5729, loss:0.5729, val_accuracy:0.6620, val_binary_crossentropy:0.5792, val_loss:0.5792,
....................................................................................................
Epoch: 1300, accuracy:0.6849, binary_crossentropy:0.5716, loss:0.5716, val_accuracy:0.6450, val_binary_crossentropy:0.5859, val_loss:0.5859,
....................................................................................................
Epoch: 1400, accuracy:0.6790, binary_crossentropy:0.5695, loss:0.5695, val_accuracy:0.6700, val_binary_crossentropy:0.5776, val_loss:0.5776,
....................................................................................................
Epoch: 1500, accuracy:0.6824, binary_crossentropy:0.5681, loss:0.5681, val_accuracy:0.6730, val_binary_crossentropy:0.5761, val_loss:0.5761,
....................................................................................................
Epoch: 1600, accuracy:0.6828, binary_crossentropy:0.5669, loss:0.5669, val_accuracy:0.6690, val_binary_crossentropy:0.5766, val_loss:0.5766,
....................................................................................................
Epoch: 1700, accuracy:0.6874, binary_crossentropy:0.5657, loss:0.5657, val_accuracy:0.6600, val_binary_crossentropy:0.5774, val_loss:0.5774,
....................................................................................................
Epoch: 1800, accuracy:0.6845, binary_crossentropy:0.5655, loss:0.5655, val_accuracy:0.6780, val_binary_crossentropy:0.5752, val_loss:0.5752,
....................................................................................................
Epoch: 1900, accuracy:0.6837, binary_crossentropy:0.5644, loss:0.5644, val_accuracy:0.6790, val_binary_crossentropy:0.5753, val_loss:0.5753,
....................................................................................................
Epoch: 2000, accuracy:0.6853, binary_crossentropy:0.5632, loss:0.5632, val_accuracy:0.6780, val_binary_crossentropy:0.5753, val_loss:0.5753,
....................................................................................................
Epoch: 2100, accuracy:0.6871, binary_crossentropy:0.5625, loss:0.5625, val_accuracy:0.6670, val_binary_crossentropy:0.5769, val_loss:0.5769,
...................................
Ahora mira cómo lo hizo el modelo:
plotter = tfdocs.plots.HistoryPlotter(metric = 'binary_crossentropy', smoothing_std=10)
plotter.plot(size_histories)
plt.ylim([0.5, 0.7])
(0.5, 0.7)
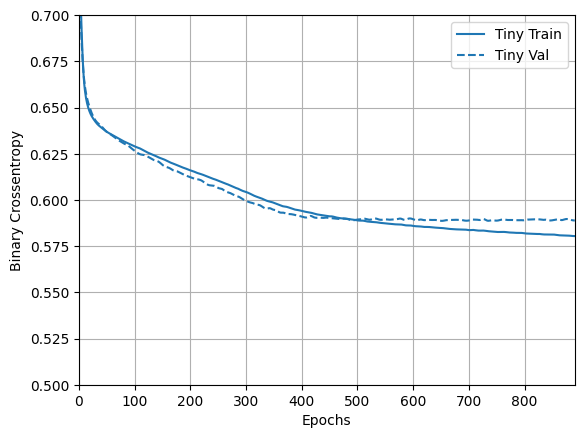
modelo pequeño
Para ver si puede superar el rendimiento del modelo pequeño, entrene progresivamente algunos modelos más grandes.
Prueba dos capas ocultas con 16 unidades cada una:
small_model = tf.keras.Sequential([
# `input_shape` is only required here so that `.summary` works.
layers.Dense(16, activation='elu', input_shape=(FEATURES,)),
layers.Dense(16, activation='elu'),
layers.Dense(1)
])
size_histories['Small'] = compile_and_fit(small_model, 'sizes/Small')
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_2 (Dense) (None, 16) 464
dense_3 (Dense) (None, 16) 272
dense_4 (Dense) (None, 1) 17
=================================================================
Total params: 753
Trainable params: 753
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.4864, binary_crossentropy:0.7769, loss:0.7769, val_accuracy:0.4930, val_binary_crossentropy:0.7211, val_loss:0.7211,
....................................................................................................
Epoch: 100, accuracy:0.6386, binary_crossentropy:0.6052, loss:0.6052, val_accuracy:0.6020, val_binary_crossentropy:0.6177, val_loss:0.6177,
....................................................................................................
Epoch: 200, accuracy:0.6697, binary_crossentropy:0.5829, loss:0.5829, val_accuracy:0.6310, val_binary_crossentropy:0.6018, val_loss:0.6018,
....................................................................................................
Epoch: 300, accuracy:0.6838, binary_crossentropy:0.5721, loss:0.5721, val_accuracy:0.6490, val_binary_crossentropy:0.5940, val_loss:0.5940,
....................................................................................................
Epoch: 400, accuracy:0.6911, binary_crossentropy:0.5656, loss:0.5656, val_accuracy:0.6430, val_binary_crossentropy:0.5985, val_loss:0.5985,
....................................................................................................
Epoch: 500, accuracy:0.6930, binary_crossentropy:0.5607, loss:0.5607, val_accuracy:0.6430, val_binary_crossentropy:0.6028, val_loss:0.6028,
.........................
modelo mediano
Ahora prueba 3 capas ocultas con 64 unidades cada una:
medium_model = tf.keras.Sequential([
layers.Dense(64, activation='elu', input_shape=(FEATURES,)),
layers.Dense(64, activation='elu'),
layers.Dense(64, activation='elu'),
layers.Dense(1)
])
Y entrena el modelo usando los mismos datos:
size_histories['Medium'] = compile_and_fit(medium_model, "sizes/Medium")
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_5 (Dense) (None, 64) 1856
dense_6 (Dense) (None, 64) 4160
dense_7 (Dense) (None, 64) 4160
dense_8 (Dense) (None, 1) 65
=================================================================
Total params: 10,241
Trainable params: 10,241
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.5017, binary_crossentropy:0.6840, loss:0.6840, val_accuracy:0.4790, val_binary_crossentropy:0.6723, val_loss:0.6723,
....................................................................................................
Epoch: 100, accuracy:0.7173, binary_crossentropy:0.5221, loss:0.5221, val_accuracy:0.6470, val_binary_crossentropy:0.6111, val_loss:0.6111,
....................................................................................................
Epoch: 200, accuracy:0.7884, binary_crossentropy:0.4270, loss:0.4270, val_accuracy:0.6390, val_binary_crossentropy:0.7045, val_loss:0.7045,
..............................................................
modelo grande
Como ejercicio, puede crear un modelo aún más grande y ver qué tan rápido comienza a sobreajustarse. A continuación, agreguemos a este punto de referencia una red que tiene mucha más capacidad, mucho más de lo que justificaría el problema:
large_model = tf.keras.Sequential([
layers.Dense(512, activation='elu', input_shape=(FEATURES,)),
layers.Dense(512, activation='elu'),
layers.Dense(512, activation='elu'),
layers.Dense(512, activation='elu'),
layers.Dense(1)
])
Y, de nuevo, entrena el modelo usando los mismos datos:
size_histories['large'] = compile_and_fit(large_model, "sizes/large")
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_9 (Dense) (None, 512) 14848
dense_10 (Dense) (None, 512) 262656
dense_11 (Dense) (None, 512) 262656
dense_12 (Dense) (None, 512) 262656
dense_13 (Dense) (None, 1) 513
=================================================================
Total params: 803,329
Trainable params: 803,329
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.5145, binary_crossentropy:0.7740, loss:0.7740, val_accuracy:0.4980, val_binary_crossentropy:0.6793, val_loss:0.6793,
....................................................................................................
Epoch: 100, accuracy:1.0000, binary_crossentropy:0.0020, loss:0.0020, val_accuracy:0.6600, val_binary_crossentropy:1.8540, val_loss:1.8540,
....................................................................................................
Epoch: 200, accuracy:1.0000, binary_crossentropy:0.0001, loss:0.0001, val_accuracy:0.6560, val_binary_crossentropy:2.5293, val_loss:2.5293,
..........................
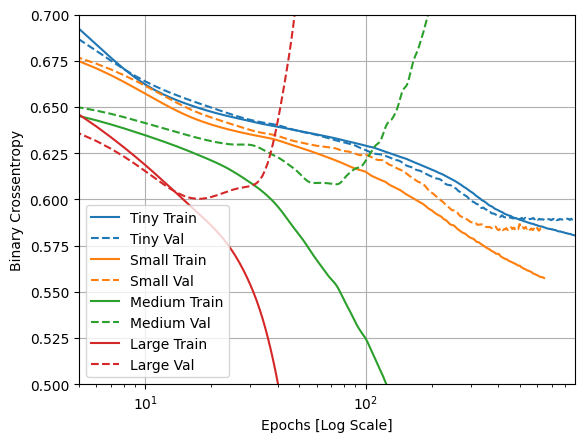
Trazar las pérdidas de entrenamiento y validación
Las líneas continuas muestran la pérdida de entrenamiento y las líneas discontinuas muestran la pérdida de validación (recuerde: una pérdida de validación más baja indica un mejor modelo).
Si bien la construcción de un modelo más grande le da más potencia, si esta potencia no está restringida de alguna manera, puede sobreajustarse fácilmente al conjunto de entrenamiento.
En este ejemplo, normalmente, solo el modelo "Tiny" logra evitar el sobreajuste por completo, y cada uno de los modelos más grandes sobreajusta los datos más rápidamente. Esto se vuelve tan grave para el modelo "large" que necesita cambiar la gráfica a una escala logarítmica para ver realmente lo que está sucediendo.
Esto es evidente si traza y compara las métricas de validación con las métricas de entrenamiento.
- Es normal que haya una pequeña diferencia.
- Si ambas métricas se mueven en la misma dirección, todo está bien.
- Si la métrica de validación comienza a estancarse mientras la métrica de entrenamiento continúa mejorando, probablemente esté cerca de sobreajustarse.
- Si la métrica de validación va en la dirección equivocada, el modelo claramente se está sobreajustando.
plotter.plot(size_histories)
a = plt.xscale('log')
plt.xlim([5, max(plt.xlim())])
plt.ylim([0.5, 0.7])
plt.xlabel("Epochs [Log Scale]")
Text(0.5, 0, 'Epochs [Log Scale]')
Ver en TensorBoard
Todos estos modelos escribieron registros de TensorBoard durante el entrenamiento.
Abra un visor de TensorBoard incrustado dentro de un cuaderno:
#docs_infra: no_execute
# Load the TensorBoard notebook extension
%load_ext tensorboard
# Open an embedded TensorBoard viewer
%tensorboard --logdir {logdir}/sizes
Puede ver los resultados de una ejecución anterior de este cuaderno en TensorBoard.dev .
TensorBoard.dev es una experiencia administrada para hospedar, rastrear y compartir experimentos de ML con todos.
También se incluye en un <iframe> para mayor comodidad:
display.IFrame(
src="https://tensorboard.dev/experiment/vW7jmmF9TmKmy3rbheMQpw/#scalars&_smoothingWeight=0.97",
width="100%", height="800px")
Si desea compartir los resultados de TensorBoard, puede cargar los registros en TensorBoard.dev copiando lo siguiente en una celda de código.
tensorboard dev upload --logdir {logdir}/sizes
Estrategias para evitar el sobreajuste
Antes de entrar en el contenido de esta sección, copie los registros de entrenamiento del modelo "Tiny" anterior, para usarlos como referencia para la comparación.
shutil.rmtree(logdir/'regularizers/Tiny', ignore_errors=True)
shutil.copytree(logdir/'sizes/Tiny', logdir/'regularizers/Tiny')
PosixPath('/tmp/tmpn1rdh98q/tensorboard_logs/regularizers/Tiny')
regularizer_histories = {}
regularizer_histories['Tiny'] = size_histories['Tiny']
Agregar regularización de peso
Puede que estés familiarizado con el principio de la navaja de Occam: dadas dos explicaciones para algo, la explicación más probable que sea correcta es la "más simple", la que hace la menor cantidad de suposiciones. Esto también se aplica a los modelos aprendidos por las redes neuronales: dados algunos datos de entrenamiento y una arquitectura de red, existen múltiples conjuntos de valores de peso (múltiples modelos) que podrían explicar los datos, y es menos probable que los modelos más simples se sobreajusten que los complejos.
Un "modelo simple" en este contexto es un modelo en el que la distribución de los valores de los parámetros tiene menos entropía (o un modelo con menos parámetros en total, como vimos en la sección anterior). Por lo tanto, una forma común de mitigar el sobreajuste es imponer restricciones a la complejidad de una red forzando sus pesos solo a tomar valores pequeños, lo que hace que la distribución de los valores de peso sea más "regular". Esto se denomina "regularización de pesos", y se realiza agregando a la función de pérdida de la red un costo asociado a tener pesos elevados. Este costo viene en dos sabores:
Regularización L1 , donde el costo agregado es proporcional al valor absoluto de los coeficientes de los pesos (es decir, a lo que se llama la "norma L1" de los pesos).
Regularización L2 , donde el costo agregado es proporcional al cuadrado del valor de los coeficientes de los pesos (es decir, a lo que se llama la "norma L2" al cuadrado de los pesos). La regularización de L2 también se denomina disminución de peso en el contexto de las redes neuronales. No deje que el nombre diferente lo confunda: la disminución del peso es matemáticamente lo mismo que la regularización L2.
La regularización L1 empuja los pesos hacia exactamente cero fomentando un modelo disperso. La regularización de L2 penalizará los parámetros de peso sin hacerlos escasos, ya que la penalización llega a cero para pesos pequeños, una de las razones por las que L2 es más común.
En tf.keras , la regularización de peso se agrega pasando instancias de regularizador de peso a capas como argumentos de palabras clave. Agreguemos ahora la regularización del peso L2.
l2_model = tf.keras.Sequential([
layers.Dense(512, activation='elu',
kernel_regularizer=regularizers.l2(0.001),
input_shape=(FEATURES,)),
layers.Dense(512, activation='elu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(512, activation='elu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(512, activation='elu',
kernel_regularizer=regularizers.l2(0.001)),
layers.Dense(1)
])
regularizer_histories['l2'] = compile_and_fit(l2_model, "regularizers/l2")
Model: "sequential_4"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_14 (Dense) (None, 512) 14848
dense_15 (Dense) (None, 512) 262656
dense_16 (Dense) (None, 512) 262656
dense_17 (Dense) (None, 512) 262656
dense_18 (Dense) (None, 1) 513
=================================================================
Total params: 803,329
Trainable params: 803,329
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.5126, binary_crossentropy:0.7481, loss:2.2415, val_accuracy:0.4950, val_binary_crossentropy:0.6707, val_loss:2.0653,
....................................................................................................
Epoch: 100, accuracy:0.6625, binary_crossentropy:0.5945, loss:0.6173, val_accuracy:0.6400, val_binary_crossentropy:0.5871, val_loss:0.6100,
....................................................................................................
Epoch: 200, accuracy:0.6690, binary_crossentropy:0.5864, loss:0.6079, val_accuracy:0.6650, val_binary_crossentropy:0.5856, val_loss:0.6076,
....................................................................................................
Epoch: 300, accuracy:0.6790, binary_crossentropy:0.5762, loss:0.5976, val_accuracy:0.6550, val_binary_crossentropy:0.5881, val_loss:0.6095,
....................................................................................................
Epoch: 400, accuracy:0.6843, binary_crossentropy:0.5697, loss:0.5920, val_accuracy:0.6650, val_binary_crossentropy:0.5878, val_loss:0.6101,
....................................................................................................
Epoch: 500, accuracy:0.6897, binary_crossentropy:0.5651, loss:0.5907, val_accuracy:0.6890, val_binary_crossentropy:0.5798, val_loss:0.6055,
....................................................................................................
Epoch: 600, accuracy:0.6945, binary_crossentropy:0.5610, loss:0.5864, val_accuracy:0.6820, val_binary_crossentropy:0.5772, val_loss:0.6026,
..........................................................
l2(0.001) significa que cada coeficiente en la matriz de peso de la capa agregará 0.001 * weight_coefficient_value**2 a la pérdida total de la red.
Es por eso que estamos monitoreando el binary_crossentropy directamente. Porque no tiene este componente de regularización mezclado.
Entonces, ese mismo modelo "Large" con una penalización de regularización L2 funciona mucho mejor:
plotter.plot(regularizer_histories)
plt.ylim([0.5, 0.7])
(0.5, 0.7)
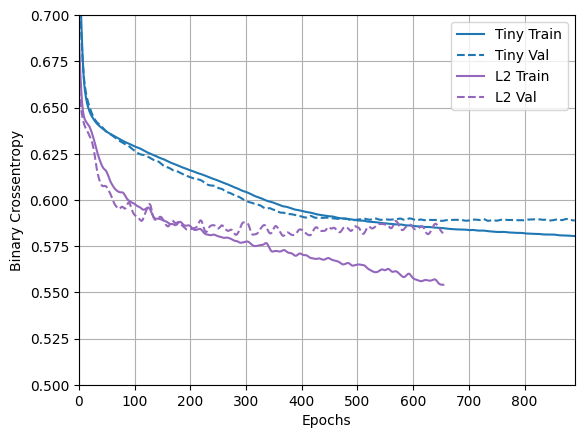
Como puede ver, el modelo regularizado "L2" ahora es mucho más competitivo que el modelo "Tiny" . Este modelo "L2" también es mucho más resistente al sobreajuste que el modelo "Large" en el que se basó a pesar de tener la misma cantidad de parámetros.
Más información
Hay dos cosas importantes a tener en cuenta sobre este tipo de regularización.
Primero: si está escribiendo su propio ciclo de entrenamiento, debe asegurarse de preguntarle al modelo por sus pérdidas de regularización.
result = l2_model(features)
regularization_loss=tf.add_n(l2_model.losses)
Segundo: esta implementación funciona agregando las penalizaciones de peso a la pérdida del modelo y luego aplicando un procedimiento de optimización estándar después de eso.
Hay un segundo enfoque que, en cambio, solo ejecuta el optimizador en la pérdida bruta, y luego, mientras aplica el paso calculado, el optimizador también aplica una disminución de peso. Esta "decadencia de peso desacoplada" se ve en optimizers.FTRL como Optimizers.FTRL y optimizers.AdamW .
Agregar abandono
Dropout es una de las técnicas de regularización más efectivas y más utilizadas para redes neuronales, desarrollada por Hinton y sus estudiantes en la Universidad de Toronto.
La explicación intuitiva para el abandono es que debido a que los nodos individuales en la red no pueden depender de la salida de los demás, cada nodo debe generar funciones que sean útiles por sí mismas.
La eliminación, aplicada a una capa, consiste en "eliminar" aleatoriamente (es decir, poner a cero) una serie de características de salida de la capa durante el entrenamiento. Digamos que una capa dada normalmente habría devuelto un vector [0.2, 0.5, 1.3, 0.8, 1.1] para una muestra de entrada dada durante el entrenamiento; después de aplicar el abandono, este vector tendrá algunas entradas cero distribuidas al azar, por ejemplo, [0, 0.5, 1.3, 0, 1.1].
La "tasa de abandono" es la fracción de las funciones que se eliminan a cero; normalmente se establece entre 0,2 y 0,5. En el momento de la prueba, no se elimina ninguna unidad y, en cambio, los valores de salida de la capa se reducen en un factor igual a la tasa de abandono, para equilibrar el hecho de que hay más unidades activas que en el momento del entrenamiento.
En tf.keras , puede introducir el abandono en una red a través de la capa de abandono, que se aplica a la salida de la capa justo antes.
Agreguemos dos capas de abandono en nuestra red para ver qué tan bien funcionan para reducir el sobreajuste:
dropout_model = tf.keras.Sequential([
layers.Dense(512, activation='elu', input_shape=(FEATURES,)),
layers.Dropout(0.5),
layers.Dense(512, activation='elu'),
layers.Dropout(0.5),
layers.Dense(512, activation='elu'),
layers.Dropout(0.5),
layers.Dense(512, activation='elu'),
layers.Dropout(0.5),
layers.Dense(1)
])
regularizer_histories['dropout'] = compile_and_fit(dropout_model, "regularizers/dropout")
Model: "sequential_5"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_19 (Dense) (None, 512) 14848
dropout (Dropout) (None, 512) 0
dense_20 (Dense) (None, 512) 262656
dropout_1 (Dropout) (None, 512) 0
dense_21 (Dense) (None, 512) 262656
dropout_2 (Dropout) (None, 512) 0
dense_22 (Dense) (None, 512) 262656
dropout_3 (Dropout) (None, 512) 0
dense_23 (Dense) (None, 1) 513
=================================================================
Total params: 803,329
Trainable params: 803,329
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.4961, binary_crossentropy:0.8110, loss:0.8110, val_accuracy:0.5330, val_binary_crossentropy:0.6900, val_loss:0.6900,
....................................................................................................
Epoch: 100, accuracy:0.6557, binary_crossentropy:0.5961, loss:0.5961, val_accuracy:0.6710, val_binary_crossentropy:0.5788, val_loss:0.5788,
....................................................................................................
Epoch: 200, accuracy:0.6871, binary_crossentropy:0.5622, loss:0.5622, val_accuracy:0.6860, val_binary_crossentropy:0.5856, val_loss:0.5856,
....................................................................................................
Epoch: 300, accuracy:0.7246, binary_crossentropy:0.5121, loss:0.5121, val_accuracy:0.6820, val_binary_crossentropy:0.5927, val_loss:0.5927,
............
plotter.plot(regularizer_histories)
plt.ylim([0.5, 0.7])
(0.5, 0.7)
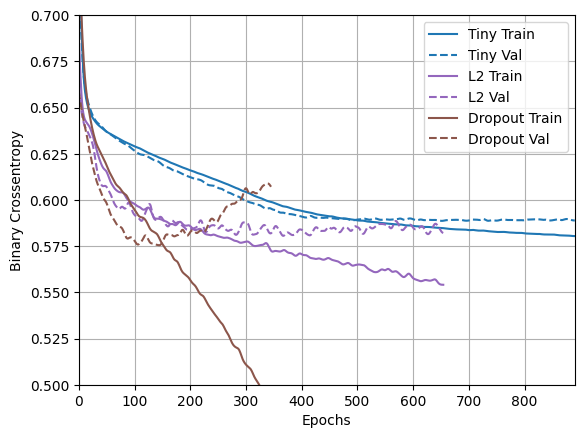
Está claro a partir de este diagrama que ambos enfoques de regularización mejoran el comportamiento del modelo "Large" . Pero esto todavía no supera ni siquiera la línea de base "Tiny" .
A continuación, pruebe ambos, juntos, y vea si funciona mejor.
Combinado L2 + abandono
combined_model = tf.keras.Sequential([
layers.Dense(512, kernel_regularizer=regularizers.l2(0.0001),
activation='elu', input_shape=(FEATURES,)),
layers.Dropout(0.5),
layers.Dense(512, kernel_regularizer=regularizers.l2(0.0001),
activation='elu'),
layers.Dropout(0.5),
layers.Dense(512, kernel_regularizer=regularizers.l2(0.0001),
activation='elu'),
layers.Dropout(0.5),
layers.Dense(512, kernel_regularizer=regularizers.l2(0.0001),
activation='elu'),
layers.Dropout(0.5),
layers.Dense(1)
])
regularizer_histories['combined'] = compile_and_fit(combined_model, "regularizers/combined")
Model: "sequential_6"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_24 (Dense) (None, 512) 14848
dropout_4 (Dropout) (None, 512) 0
dense_25 (Dense) (None, 512) 262656
dropout_5 (Dropout) (None, 512) 0
dense_26 (Dense) (None, 512) 262656
dropout_6 (Dropout) (None, 512) 0
dense_27 (Dense) (None, 512) 262656
dropout_7 (Dropout) (None, 512) 0
dense_28 (Dense) (None, 1) 513
=================================================================
Total params: 803,329
Trainable params: 803,329
Non-trainable params: 0
_________________________________________________________________
Epoch: 0, accuracy:0.5090, binary_crossentropy:0.8064, loss:0.9648, val_accuracy:0.4660, val_binary_crossentropy:0.6877, val_loss:0.8454,
....................................................................................................
Epoch: 100, accuracy:0.6445, binary_crossentropy:0.6050, loss:0.6350, val_accuracy:0.6630, val_binary_crossentropy:0.5871, val_loss:0.6169,
....................................................................................................
Epoch: 200, accuracy:0.6660, binary_crossentropy:0.5932, loss:0.6186, val_accuracy:0.6880, val_binary_crossentropy:0.5722, val_loss:0.5975,
....................................................................................................
Epoch: 300, accuracy:0.6697, binary_crossentropy:0.5818, loss:0.6100, val_accuracy:0.6900, val_binary_crossentropy:0.5614, val_loss:0.5895,
....................................................................................................
Epoch: 400, accuracy:0.6749, binary_crossentropy:0.5742, loss:0.6046, val_accuracy:0.6870, val_binary_crossentropy:0.5576, val_loss:0.5881,
....................................................................................................
Epoch: 500, accuracy:0.6854, binary_crossentropy:0.5703, loss:0.6029, val_accuracy:0.6970, val_binary_crossentropy:0.5458, val_loss:0.5784,
....................................................................................................
Epoch: 600, accuracy:0.6806, binary_crossentropy:0.5673, loss:0.6015, val_accuracy:0.6980, val_binary_crossentropy:0.5453, val_loss:0.5795,
....................................................................................................
Epoch: 700, accuracy:0.6937, binary_crossentropy:0.5583, loss:0.5938, val_accuracy:0.6870, val_binary_crossentropy:0.5477, val_loss:0.5832,
....................................................................................................
Epoch: 800, accuracy:0.6911, binary_crossentropy:0.5576, loss:0.5947, val_accuracy:0.7000, val_binary_crossentropy:0.5446, val_loss:0.5817,
.......................
plotter.plot(regularizer_histories)
plt.ylim([0.5, 0.7])
(0.5, 0.7)
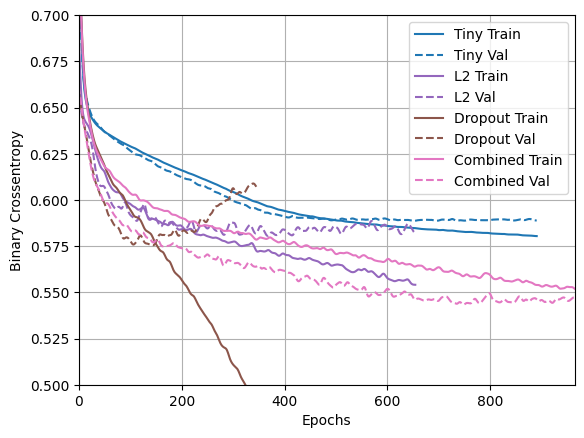
Este modelo con la regularización "Combined" es obviamente el mejor hasta ahora.
Ver en TensorBoard
Estos modelos también registraron registros de TensorBoard.
Para abrir un visor de tensorboard incrustado dentro de un cuaderno, copie lo siguiente en una celda de código:
%tensorboard --logdir {logdir}/regularizers
Puede ver los resultados de una ejecución anterior de este cuaderno en TensorDoard.dev .
También se incluye en un <iframe> para mayor comodidad:
display.IFrame(
src="https://tensorboard.dev/experiment/fGInKDo8TXes1z7HQku9mw/#scalars&_smoothingWeight=0.97",
width = "100%",
height="800px")
Esto fue subido con:
tensorboard dev upload --logdir {logdir}/regularizers
Conclusiones
En resumen: estas son las formas más comunes de evitar el sobreajuste en las redes neuronales:
- Obtén más datos de entrenamiento.
- Reducir la capacidad de la red.
- Añadir regularización de peso.
- Añadir abandono.
Dos enfoques importantes que no se cubren en esta guía son:
- aumento de datos
- normalización por lotes
Recuerde que cada método puede ayudar por sí solo, pero a menudo combinarlos puede ser aún más efectivo.
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.