
Genel Bakış
TensorFlow Model Analizi (TFMA), model değerlendirmesinin gerçekleştirilmesine yönelik bir kütüphanedir.
- Kim için : Makine Öğrenimi Mühendisleri veya Veri Bilimcileri
- Kim : TensorFlow modellerini analiz etmek ve anlamak istiyor
- bu : bağımsız bir kitaplık veya TFX işlem hattının bileşeni
- yani : büyük miktarda veri üzerindeki modelleri, eğitimde tanımlanan aynı metriklere göre dağıtılmış bir şekilde değerlendirir. Bu ölçümler veri dilimleri üzerinden karşılaştırılır ve Jupyter veya Colab not defterlerinde görselleştirilir.
- aksine : model iç gözlemi sunan tensorboard gibi bazı model iç gözlem araçları
TFMA, hesaplamalarını Apache Beam kullanarak büyük miktarda veri üzerinde dağıtılmış bir şekilde gerçekleştirir. Aşağıdaki bölümlerde temel bir TFMA değerlendirme hattının nasıl kurulacağı açıklanmaktadır. Temel uygulamaya ilişkin mimarinin daha fazla ayrıntısına bakın.
Hemen başlamak ve başlamak istiyorsanız ortak çalışma not defterimize göz atın.
Bu sayfa tensorflow.org adresinden de görüntülenebilir.
Desteklenen Model Türleri
TFMA, tensor akışı tabanlı modelleri desteklemek üzere tasarlanmıştır ancak diğer çerçeveleri de destekleyecek şekilde kolaylıkla genişletilebilir. Geçmişte TFMA, TFMA'yı kullanmak için bir EvalSavedModel oluşturulmasını gerektiriyordu ancak TFMA'nın en son sürümü, kullanıcının ihtiyaçlarına bağlı olarak birden fazla model türünü destekler. EvalSavedModel'in ayarlanması yalnızca tf.estimator tabanlı bir model kullanılıyorsa ve özel eğitim süresi ölçümleri gerekliyse gerekli olmalıdır.
TFMA artık sunum modeline göre çalıştığından, TFMA'nın artık eğitim zamanında eklenen metrikleri otomatik olarak değerlendirmeyeceğini unutmayın. Bu durumun istisnası, keras'ın kaydedilen modelin yanında kullanılan metrikleri kaydettiği için bir keras modelinin kullanılmasıdır. Ancak bu zor bir gereklilikse, en son TFMA geriye dönük olarak uyumludur, böylece EvalSavedModel hala bir TFMA hattında çalıştırılabilir.
Aşağıdaki tabloda varsayılan olarak desteklenen modeller özetlenmektedir:
| Modeli Türü | Eğitim Süresi Metrikleri | Eğitim Sonrası Metrikler |
|---|---|---|
| TF2 (keralar) | Evet* | e |
| TF2 (genel) | Yok | e |
| EvalSavedModel (tahmin edici) | e | e |
| Yok (pd.DataFrame, vb.) | Yok | e |
- Eğitim Süresi ölçümleri, eğitim zamanında tanımlanan ve modelle birlikte kaydedilen ölçümleri ifade eder (TFMA EvalSavedModel veya keras kayıtlı modeli). Eğitim sonrası ölçümler,
tfma.MetricConfigaracılığıyla eklenen ölçümleri ifade eder. - Genel TF2 modelleri, çıkarım için kullanılabilecek imzaları dışa aktaran ve keras veya tahminciye dayalı olmayan özel modellerdir.
Bu farklı model türlerinin nasıl kurulacağı ve yapılandırılacağı hakkında daha fazla bilgi için SSS'ye bakın.
Kurmak
Bir değerlendirmeyi çalıştırmadan önce az miktarda kurulum yapılması gerekir. İlk olarak, değerlendirilecek model, metrikler ve dilimler için spesifikasyonlar sağlayan bir tfma.EvalConfig nesnesi tanımlanmalıdır. İkinci olarak, değerlendirme sırasında kullanılacak gerçek modele (veya modellere) işaret eden bir tfma.EvalSharedModel oluşturulması gerekir. Bunlar tanımlandıktan sonra uygun bir veri seti ile tfma.run_model_analysis çağrılarak değerlendirme gerçekleştirilir. Daha fazla ayrıntı için kurulum kılavuzuna bakın.
Bir TFX işlem hattı içinde çalışıyorsanız, TFMA'nın bir TFX Evaluator bileşeni olarak çalışacak şekilde nasıl yapılandırılacağını öğrenmek için TFX kılavuzuna bakın.
Örnekler
Tek Model Değerlendirmesi
Aşağıda, bir sunum modelinde değerlendirme gerçekleştirmek için tfma.run_model_analysis kullanılmaktadır. Gerekli farklı ayarların açıklaması için kurulum kılavuzuna bakın.
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
eval_result = tfma.run_model_analysis(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path='/path/for/output')
tfma.view.render_slicing_metrics(eval_result)
Dağıtılmış değerlendirme için, dağıtılmış bir çalıştırıcı kullanarak bir Apache Beam işlem hattı oluşturun. İşlem hattında, değerlendirme için ve sonuçları yazmak için tfma.ExtractEvaluateAndWriteResults öğesini kullanın. Sonuçlar tfma.load_eval_result kullanılarak görselleştirme için yüklenebilir.
Örneğin:
# To run the pipeline.
from google.protobuf import text_format
from tfx_bsl.tfxio import tf_example_record
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics { class_name: "AUC" }
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_model = tfma.default_eval_shared_model(
eval_saved_model_path='/path/to/saved/model', eval_config=eval_config)
output_path = '/path/for/output'
tfx_io = tf_example_record.TFExampleRecord(
file_pattern=data_location, raw_record_column_name=tfma.ARROW_INPUT_COLUMN)
with beam.Pipeline(runner=...) as p:
_ = (p
# You can change the source as appropriate, e.g. read from BigQuery.
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format. If using EvalSavedModel then use the following
# instead: 'ReadData' >> beam.io.ReadFromTFRecord(file_pattern=...)
| 'ReadData' >> tfx_io.BeamSource()
| 'ExtractEvaluateAndWriteResults' >>
tfma.ExtractEvaluateAndWriteResults(
eval_shared_model=eval_shared_model,
eval_config=eval_config,
output_path=output_path))
# To load and visualize results.
# Note that this code should be run in a Jupyter Notebook.
result = tfma.load_eval_result(output_path)
tfma.view.render_slicing_metrics(result)
Model Doğrulaması
Bir aday ve taban çizgisine göre model doğrulaması gerçekleştirmek için, yapılandırmayı bir eşik ayarı içerecek şekilde güncelleyin ve iki modeli tfma.run_model_analysis iletin.
Örneğin:
# Run in a Jupyter Notebook.
from google.protobuf import text_format
eval_config = text_format.Parse("""
## Model information
model_specs {
# This assumes a serving model with a "serving_default" signature.
label_key: "label"
example_weight_key: "weight"
}
## Post export metric information
metrics_specs {
# This adds AUC and as a post training metric. If the model has built in
# training metrics which also contains AUC, this metric will replace it.
metrics {
class_name: "AUC"
threshold {
value_threshold {
lower_bound { value: 0.9 }
}
change_threshold {
direction: HIGHER_IS_BETTER
absolute { value: -1e-10 }
}
}
}
# ... other post training metrics ...
# Plots are also configured here...
metrics { class_name: "ConfusionMatrixPlot" }
}
## Slicing information
slicing_specs {} # overall slice
slicing_specs {
feature_keys: ["age"]
}
""", tfma.EvalConfig())
eval_shared_models = [
tfma.default_eval_shared_model(
model_name=tfma.CANDIDATE_KEY,
eval_saved_model_path='/path/to/saved/candiate/model',
eval_config=eval_config),
tfma.default_eval_shared_model(
model_name=tfma.BASELINE_KEY,
eval_saved_model_path='/path/to/saved/baseline/model',
eval_config=eval_config),
]
output_path = '/path/for/output'
eval_result = tfma.run_model_analysis(
eval_shared_models,
eval_config=eval_config,
# This assumes your data is a TFRecords file containing records in the
# tf.train.Example format.
data_location='/path/to/file/containing/tfrecords',
output_path=output_path)
tfma.view.render_slicing_metrics(eval_result)
tfma.load_validation_result(output_path)
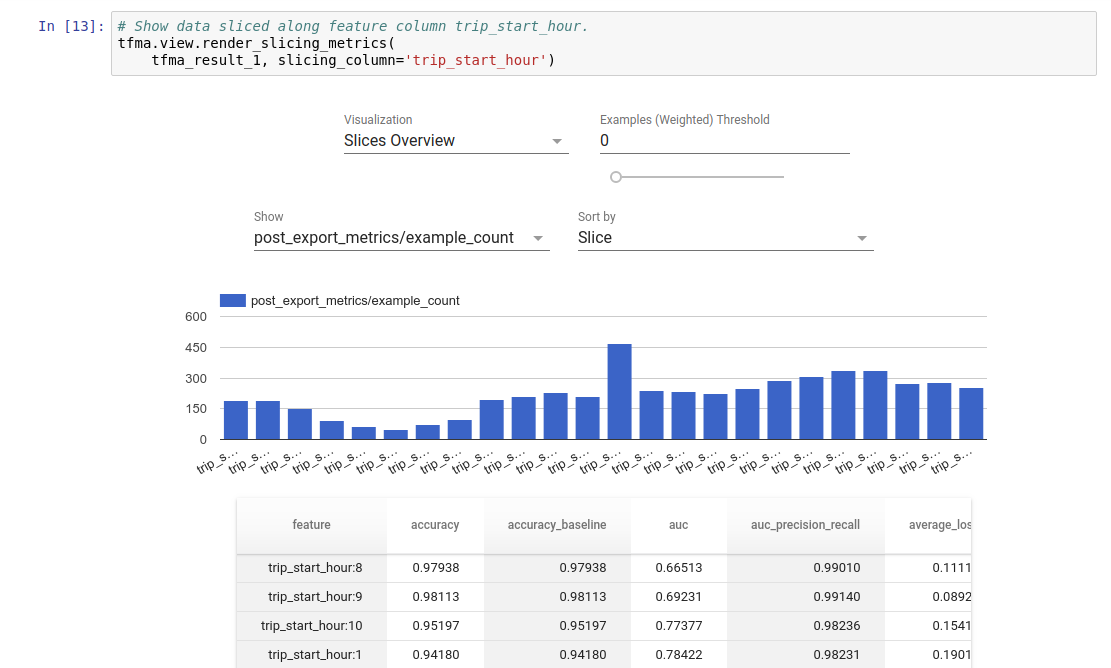
Görselleştirme
TFMA değerlendirme sonuçları, TFMA'da bulunan ön uç bileşenleri kullanılarak bir Jupyter dizüstü bilgisayarda görselleştirilebilir. Örneğin:
 .
.