
| | |  Ver fuente en GitHub Ver fuente en GitHub | |
Este tutorial muestra cómo clasificar imágenes de flores. Crea un clasificador de imágenes usando un modelo tf.keras.Sequential y carga datos usando tf.keras.utils.image_dataset_from_directory . Adquirirás experiencia práctica con los siguientes conceptos:
- Carga eficiente de un conjunto de datos fuera del disco.
- Identificar el sobreajuste y aplicar técnicas para mitigarlo, incluido el aumento y la eliminación de datos.
Este tutorial sigue un flujo de trabajo básico de aprendizaje automático:
- Examinar y comprender los datos.
- Crear una canalización de entrada
- Construye el modelo
- entrenar al modelo
- Probar el modelo
- Mejorar el modelo y repetir el proceso
Importar TensorFlow y otras bibliotecas
import matplotlib.pyplot as plt
import numpy as np
import os
import PIL
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Sequential
Descargar y explorar el conjunto de datos
Este tutorial utiliza un conjunto de datos de unas 3700 fotos de flores. El conjunto de datos contiene cinco subdirectorios, uno por clase:
flower_photo/
daisy/
dandelion/
roses/
sunflowers/
tulips/
import pathlib
dataset_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
data_dir = tf.keras.utils.get_file('flower_photos', origin=dataset_url, untar=True)
data_dir = pathlib.Path(data_dir)
Después de la descarga, ahora debería tener una copia del conjunto de datos disponible. Hay 3.670 imágenes en total:
image_count = len(list(data_dir.glob('*/*.jpg')))
print(image_count)
3670
Aquí hay algunas rosas:
roses = list(data_dir.glob('roses/*'))
PIL.Image.open(str(roses[0]))

PIL.Image.open(str(roses[1]))

Y unos tulipanes:
tulips = list(data_dir.glob('tulips/*'))
PIL.Image.open(str(tulips[0]))

PIL.Image.open(str(tulips[1]))
Cargue datos usando una utilidad Keras
Carguemos estas imágenes fuera del disco utilizando la útil utilidad tf.keras.utils.image_dataset_from_directory . Esto lo llevará de un directorio de imágenes en el disco a un tf.data.Dataset en solo un par de líneas de código. Si lo desea, también puede escribir su propio código de carga de datos desde cero visitando el tutorial Cargar y preprocesar imágenes .
Crear un conjunto de datos
Defina algunos parámetros para el cargador:
batch_size = 32
img_height = 180
img_width = 180
Es una buena práctica usar una división de validación al desarrollar su modelo. Usemos el 80% de las imágenes para entrenamiento y el 20% para validación.
train_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 2936 files for training.
val_ds = tf.keras.utils.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=123,
image_size=(img_height, img_width),
batch_size=batch_size)
Found 3670 files belonging to 5 classes. Using 734 files for validation.
Puede encontrar los nombres de clase en el atributo class_names en estos conjuntos de datos. Estos corresponden a los nombres de los directorios en orden alfabético.
class_names = train_ds.class_names
print(class_names)
['daisy', 'dandelion', 'roses', 'sunflowers', 'tulips']
Visualiza los datos
Aquí están las primeras nueve imágenes del conjunto de datos de entrenamiento:
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(class_names[labels[i]])
plt.axis("off")
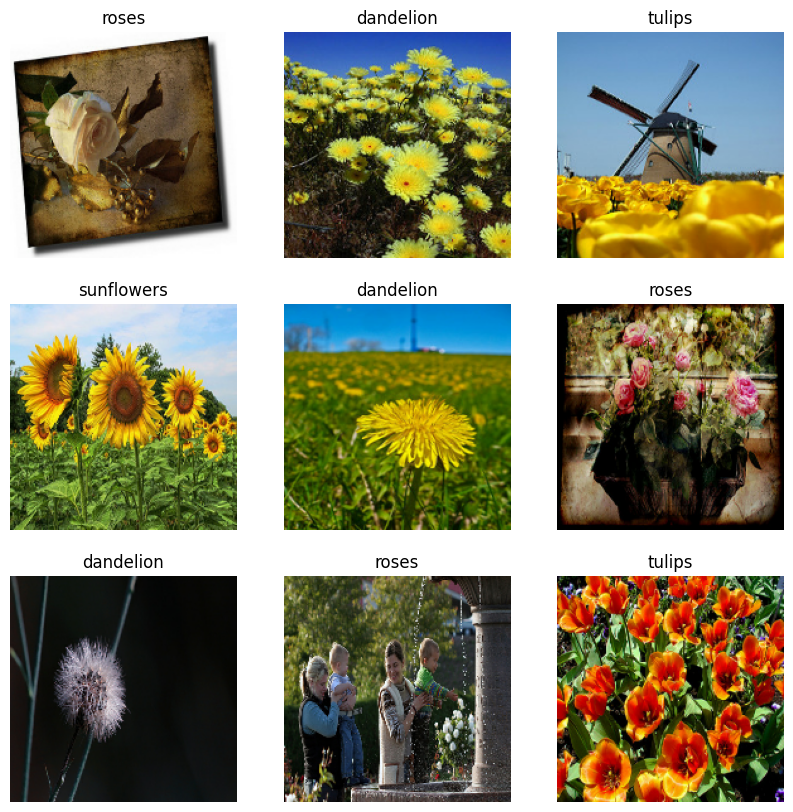
Entrenará un modelo usando estos conjuntos de datos pasándolos a Model.fit en un momento. Si lo desea, también puede iterar manualmente sobre el conjunto de datos y recuperar lotes de imágenes:
for image_batch, labels_batch in train_ds:
print(image_batch.shape)
print(labels_batch.shape)
break
(32, 180, 180, 3) (32,)
image_batch es un tensor de la forma (32, 180, 180, 3) . Este es un lote de 32 imágenes de forma 180x180x3 (la última dimensión se refiere a los canales de color RGB). El label_batch es un tensor de la forma (32,) , estas son las etiquetas correspondientes a las 32 imágenes.
Puede llamar a .numpy() en los tensores image_batch y labels_batch para convertirlos en numpy.ndarray .
Configurar el conjunto de datos para el rendimiento
Asegurémonos de utilizar la captación previa almacenada en búfer para que pueda obtener datos del disco sin que la E/S se convierta en un bloqueo. Estos son dos métodos importantes que debe usar al cargar datos:
-
Dataset.cachemantiene las imágenes en la memoria después de que se cargan fuera del disco durante la primera época. Esto asegurará que el conjunto de datos no se convierta en un cuello de botella mientras entrena su modelo. Si su conjunto de datos es demasiado grande para caber en la memoria, también puede usar este método para crear un caché en disco de alto rendimiento. -
Dataset.prefetchsuperpone el preprocesamiento de datos y la ejecución del modelo durante el entrenamiento.
Los lectores interesados pueden obtener más información sobre ambos métodos, así como sobre cómo almacenar datos en caché en el disco, en la sección Precarga de la guía Mejor rendimiento con la API tf.data .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().shuffle(1000).prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Estandarizar los datos
Los valores del canal RGB están en el rango [0, 255] . Esto no es ideal para una red neuronal; en general, debe buscar que sus valores de entrada sean pequeños.
Aquí, estandarizará los valores para que estén en el rango [0, 1] usando tf.keras.layers.Rescaling :
normalization_layer = layers.Rescaling(1./255)
Hay dos formas de usar esta capa. Puede aplicarlo al conjunto de datos llamando a Dataset.map :
normalized_ds = train_ds.map(lambda x, y: (normalization_layer(x), y))
image_batch, labels_batch = next(iter(normalized_ds))
first_image = image_batch[0]
# Notice the pixel values are now in `[0,1]`.
print(np.min(first_image), np.max(first_image))
0.0 1.0
O bien, puede incluir la capa dentro de la definición de su modelo, lo que puede simplificar la implementación. Usemos el segundo enfoque aquí.
Crear el modelo
El modelo secuencial consta de tres bloques de convolución ( tf.keras.layers.Conv2D ) con una capa de agrupación máxima ( tf.keras.layers.MaxPooling2D ) en cada uno de ellos. Hay una capa totalmente conectada ( tf.keras.layers.Dense ) con 128 unidades encima que se activa mediante una función de activación de ReLU ( 'relu' ). Este modelo no se ha ajustado para una alta precisión; el objetivo de este tutorial es mostrar un enfoque estándar.
num_classes = len(class_names)
model = Sequential([
layers.Rescaling(1./255, input_shape=(img_height, img_width, 3)),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Compilar el modelo
Para este tutorial, elija el optimizador tf.keras.optimizers.Adam y la función de pérdida tf.keras.losses.SparseCategoricalCrossentropy . Para ver la precisión del entrenamiento y la validación para cada época de entrenamiento, pase el argumento de metrics a Model.compile .
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Resumen Modelo
Vea todas las capas de la red utilizando el método Model.summary del modelo:
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
rescaling_1 (Rescaling) (None, 180, 180, 3) 0
conv2d (Conv2D) (None, 180, 180, 16) 448
max_pooling2d (MaxPooling2D (None, 90, 90, 16) 0
)
conv2d_1 (Conv2D) (None, 90, 90, 32) 4640
max_pooling2d_1 (MaxPooling (None, 45, 45, 32) 0
2D)
conv2d_2 (Conv2D) (None, 45, 45, 64) 18496
max_pooling2d_2 (MaxPooling (None, 22, 22, 64) 0
2D)
flatten (Flatten) (None, 30976) 0
dense (Dense) (None, 128) 3965056
dense_1 (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________
entrenar al modelo
epochs=10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/10 92/92 [==============================] - 3s 16ms/step - loss: 1.2769 - accuracy: 0.4489 - val_loss: 1.0457 - val_accuracy: 0.5804 Epoch 2/10 92/92 [==============================] - 1s 11ms/step - loss: 0.9386 - accuracy: 0.6328 - val_loss: 0.9665 - val_accuracy: 0.6158 Epoch 3/10 92/92 [==============================] - 1s 11ms/step - loss: 0.7390 - accuracy: 0.7200 - val_loss: 0.8768 - val_accuracy: 0.6540 Epoch 4/10 92/92 [==============================] - 1s 11ms/step - loss: 0.5649 - accuracy: 0.7963 - val_loss: 0.9258 - val_accuracy: 0.6540 Epoch 5/10 92/92 [==============================] - 1s 11ms/step - loss: 0.3662 - accuracy: 0.8733 - val_loss: 1.1734 - val_accuracy: 0.6267 Epoch 6/10 92/92 [==============================] - 1s 11ms/step - loss: 0.2169 - accuracy: 0.9343 - val_loss: 1.3728 - val_accuracy: 0.6499 Epoch 7/10 92/92 [==============================] - 1s 11ms/step - loss: 0.1191 - accuracy: 0.9629 - val_loss: 1.3791 - val_accuracy: 0.6471 Epoch 8/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0497 - accuracy: 0.9871 - val_loss: 1.8002 - val_accuracy: 0.6390 Epoch 9/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0372 - accuracy: 0.9922 - val_loss: 1.8545 - val_accuracy: 0.6390 Epoch 10/10 92/92 [==============================] - 1s 11ms/step - loss: 0.0715 - accuracy: 0.9813 - val_loss: 2.0656 - val_accuracy: 0.6049
Visualiza los resultados del entrenamiento
Cree gráficos de pérdida y precisión en los conjuntos de entrenamiento y validación:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
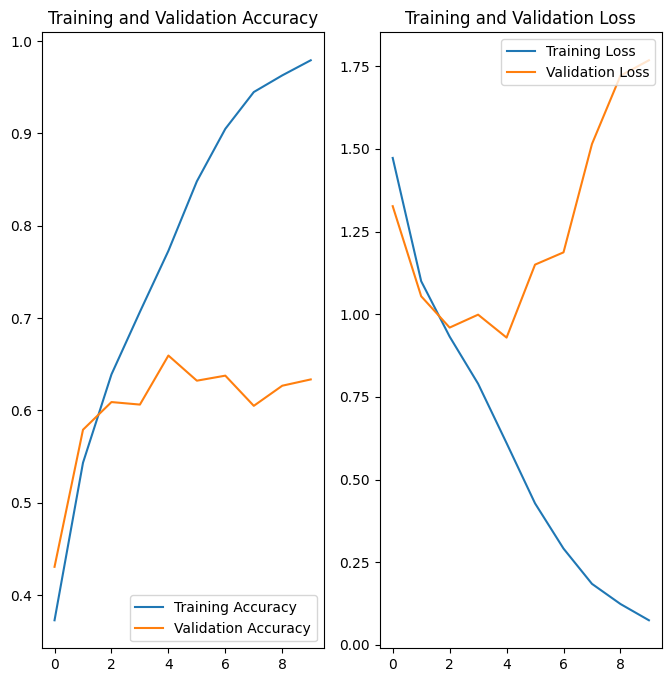
Los gráficos muestran que la precisión del entrenamiento y la precisión de la validación están desviadas por amplios márgenes, y el modelo ha logrado solo alrededor del 60 % de precisión en el conjunto de validación.
Inspeccionemos qué salió mal e intentemos aumentar el rendimiento general del modelo.
sobreajuste
En los gráficos anteriores, la precisión del entrenamiento aumenta linealmente con el tiempo, mientras que la precisión de la validación se detiene alrededor del 60 % en el proceso de entrenamiento. Además, la diferencia en la precisión entre la precisión del entrenamiento y la validación es notable, un signo de sobreajuste .
Cuando hay una pequeña cantidad de ejemplos de entrenamiento, el modelo a veces aprende de los ruidos o detalles no deseados de los ejemplos de entrenamiento, hasta el punto de afectar negativamente el rendimiento del modelo en los nuevos ejemplos. Este fenómeno se conoce como sobreajuste. Significa que el modelo tendrá dificultades para generalizar en un nuevo conjunto de datos.
Hay múltiples formas de combatir el sobreajuste en el proceso de entrenamiento. En este tutorial, utilizará el aumento de datos y agregará Dropout a su modelo.
Aumento de datos
El sobreajuste generalmente ocurre cuando hay una pequeña cantidad de ejemplos de entrenamiento. El aumento de datos adopta el enfoque de generar datos de entrenamiento adicionales a partir de sus ejemplos existentes al aumentarlos mediante transformaciones aleatorias que producen imágenes de aspecto creíble. Esto ayuda a exponer el modelo a más aspectos de los datos y a generalizar mejor.
Implementará el aumento de datos utilizando las siguientes capas de preprocesamiento de Keras: tf.keras.layers.RandomFlip , tf.keras.layers.RandomRotation y tf.keras.layers.RandomZoom . Estos pueden incluirse dentro de su modelo como otras capas y ejecutarse en la GPU.
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal",
input_shape=(img_height,
img_width,
3)),
layers.RandomRotation(0.1),
layers.RandomZoom(0.1),
]
)
Visualicemos cómo se ven algunos ejemplos aumentados aplicando el aumento de datos a la misma imagen varias veces:
plt.figure(figsize=(10, 10))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")

Utilizará el aumento de datos para entrenar un modelo en un momento.
Abandonar
Otra técnica para reducir el sobreajuste es introducir la regularización de abandonos en la red.
Cuando aplica abandono a una capa, descarta aleatoriamente (estableciendo la activación en cero) una cantidad de unidades de salida de la capa durante el proceso de entrenamiento. Dropout toma un número fraccionario como su valor de entrada, en forma de 0.1, 0.2, 0.4, etc. Esto significa eliminar aleatoriamente el 10%, 20% o 40% de las unidades de salida de la capa aplicada.
Vamos a crear una nueva red neuronal con tf.keras.layers.Dropout antes de entrenarla usando las imágenes aumentadas:
model = Sequential([
data_augmentation,
layers.Rescaling(1./255),
layers.Conv2D(16, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(32, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Conv2D(64, 3, padding='same', activation='relu'),
layers.MaxPooling2D(),
layers.Dropout(0.2),
layers.Flatten(),
layers.Dense(128, activation='relu'),
layers.Dense(num_classes)
])
Compilar y entrenar el modelo.
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
sequential_1 (Sequential) (None, 180, 180, 3) 0
rescaling_2 (Rescaling) (None, 180, 180, 3) 0
conv2d_3 (Conv2D) (None, 180, 180, 16) 448
max_pooling2d_3 (MaxPooling (None, 90, 90, 16) 0
2D)
conv2d_4 (Conv2D) (None, 90, 90, 32) 4640
max_pooling2d_4 (MaxPooling (None, 45, 45, 32) 0
2D)
conv2d_5 (Conv2D) (None, 45, 45, 64) 18496
max_pooling2d_5 (MaxPooling (None, 22, 22, 64) 0
2D)
dropout (Dropout) (None, 22, 22, 64) 0
flatten_1 (Flatten) (None, 30976) 0
dense_2 (Dense) (None, 128) 3965056
dense_3 (Dense) (None, 5) 645
=================================================================
Total params: 3,989,285
Trainable params: 3,989,285
Non-trainable params: 0
_________________________________________________________________
epochs = 15
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
Epoch 1/15 92/92 [==============================] - 2s 14ms/step - loss: 1.3840 - accuracy: 0.3999 - val_loss: 1.0967 - val_accuracy: 0.5518 Epoch 2/15 92/92 [==============================] - 1s 12ms/step - loss: 1.1152 - accuracy: 0.5395 - val_loss: 1.1123 - val_accuracy: 0.5545 Epoch 3/15 92/92 [==============================] - 1s 12ms/step - loss: 1.0049 - accuracy: 0.6052 - val_loss: 0.9544 - val_accuracy: 0.6253 Epoch 4/15 92/92 [==============================] - 1s 12ms/step - loss: 0.9452 - accuracy: 0.6257 - val_loss: 0.9681 - val_accuracy: 0.6213 Epoch 5/15 92/92 [==============================] - 1s 12ms/step - loss: 0.8804 - accuracy: 0.6591 - val_loss: 0.8450 - val_accuracy: 0.6798 Epoch 6/15 92/92 [==============================] - 1s 12ms/step - loss: 0.8001 - accuracy: 0.6945 - val_loss: 0.8715 - val_accuracy: 0.6594 Epoch 7/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7736 - accuracy: 0.6965 - val_loss: 0.8059 - val_accuracy: 0.6935 Epoch 8/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7477 - accuracy: 0.7078 - val_loss: 0.8292 - val_accuracy: 0.6812 Epoch 9/15 92/92 [==============================] - 1s 12ms/step - loss: 0.7053 - accuracy: 0.7251 - val_loss: 0.7743 - val_accuracy: 0.6989 Epoch 10/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6884 - accuracy: 0.7340 - val_loss: 0.7867 - val_accuracy: 0.6907 Epoch 11/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6536 - accuracy: 0.7469 - val_loss: 0.7732 - val_accuracy: 0.6785 Epoch 12/15 92/92 [==============================] - 1s 12ms/step - loss: 0.6456 - accuracy: 0.7500 - val_loss: 0.7801 - val_accuracy: 0.6907 Epoch 13/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5941 - accuracy: 0.7735 - val_loss: 0.7185 - val_accuracy: 0.7330 Epoch 14/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5824 - accuracy: 0.7735 - val_loss: 0.7282 - val_accuracy: 0.7357 Epoch 15/15 92/92 [==============================] - 1s 12ms/step - loss: 0.5771 - accuracy: 0.7851 - val_loss: 0.7308 - val_accuracy: 0.7343
Visualiza los resultados del entrenamiento
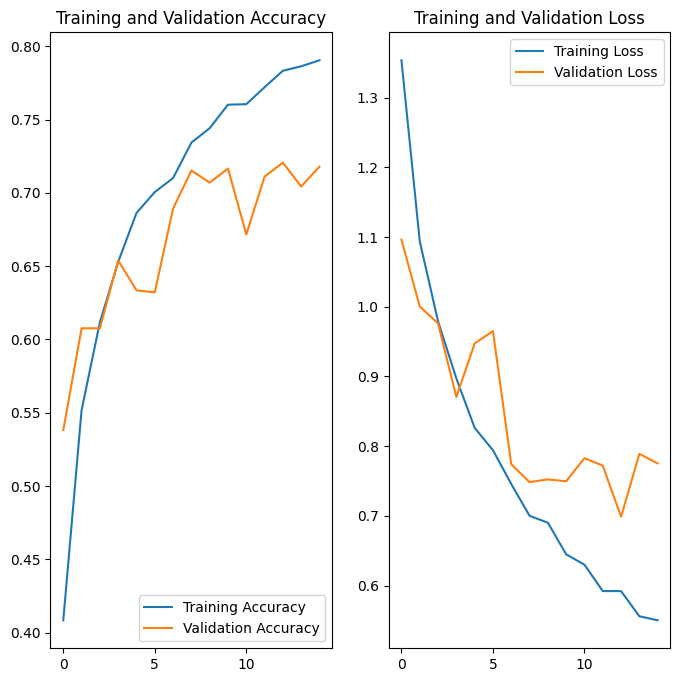
Después de aplicar el aumento de datos y tf.keras.layers.Dropout , hay menos sobreajuste que antes, y la precisión del entrenamiento y la validación están más alineadas:
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
Predecir con nuevos datos
Finalmente, usemos nuestro modelo para clasificar una imagen que no se incluyó en los conjuntos de entrenamiento o validación.
sunflower_url = "https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg"
sunflower_path = tf.keras.utils.get_file('Red_sunflower', origin=sunflower_url)
img = tf.keras.utils.load_img(
sunflower_path, target_size=(img_height, img_width)
)
img_array = tf.keras.utils.img_to_array(img)
img_array = tf.expand_dims(img_array, 0) # Create a batch
predictions = model.predict(img_array)
score = tf.nn.softmax(predictions[0])
print(
"This image most likely belongs to {} with a {:.2f} percent confidence."
.format(class_names[np.argmax(score)], 100 * np.max(score))
)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/example_images/592px-Red_sunflower.jpg 122880/117948 [===============================] - 0s 0us/step 131072/117948 [=================================] - 0s 0us/step This image most likely belongs to sunflowers with a 89.13 percent confidence.