
| | |  GitHub पर स्रोत देखें GitHub पर स्रोत देखें | |
एक प्रतिगमन समस्या में, उद्देश्य एक निरंतर मूल्य के उत्पादन की भविष्यवाणी करना है, जैसे मूल्य या संभावना। एक वर्गीकरण समस्या के साथ इसकी तुलना करें, जहां उद्देश्य कक्षाओं की सूची से एक वर्ग का चयन करना है (उदाहरण के लिए, जहां एक चित्र में एक सेब या एक नारंगी होता है, यह पहचानना कि चित्र में कौन सा फल है)।
यह ट्यूटोरियल क्लासिक ऑटो एमपीजी डेटासेट का उपयोग करता है और दर्शाता है कि 1970 के दशक के अंत और 1980 के दशक की शुरुआत में ऑटोमोबाइल की ईंधन दक्षता का अनुमान लगाने के लिए मॉडल कैसे बनाया जाए। ऐसा करने के लिए, आप उस समय अवधि के कई ऑटोमोबाइल के विवरण के साथ मॉडल प्रदान करेंगे। इस विवरण में सिलेंडर, विस्थापन, अश्वशक्ति और वजन जैसी विशेषताएं शामिल हैं।
यह उदाहरण केरस एपीआई का उपयोग करता है। (अधिक जानने के लिए केरस ट्यूटोरियल और गाइड पर जाएं।)
# Use seaborn for pairplot.pip install -q seaborn
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
# Make NumPy printouts easier to read.
np.set_printoptions(precision=3, suppress=True)
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
print(tf.__version__)
2.8.0-rc1
ऑटो एमपीजी डेटासेट
डेटासेट यूसीआई मशीन लर्निंग रिपोजिटरी से उपलब्ध है।
डेटा प्राप्त करें
पहले पांडा का उपयोग करके डेटासेट डाउनलोड और आयात करें:
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/auto-mpg/auto-mpg.data'
column_names = ['MPG', 'Cylinders', 'Displacement', 'Horsepower', 'Weight',
'Acceleration', 'Model Year', 'Origin']
raw_dataset = pd.read_csv(url, names=column_names,
na_values='?', comment='\t',
sep=' ', skipinitialspace=True)
dataset = raw_dataset.copy()
dataset.tail()
डेटा साफ़ करें
डेटासेट में कुछ अज्ञात मान हैं:
dataset.isna().sum()
MPG 0 Cylinders 0 Displacement 0 Horsepower 6 Weight 0 Acceleration 0 Model Year 0 Origin 0 dtype: int64
इस प्रारंभिक ट्यूटोरियल को सरल रखने के लिए उन पंक्तियों को छोड़ दें:
dataset = dataset.dropna()
"Origin" कॉलम श्रेणीबद्ध है, संख्यात्मक नहीं। तो अगला चरण pd.get_dummies के साथ कॉलम में मानों को एक-हॉट एन्कोड करना है।
dataset['Origin'] = dataset['Origin'].map({1: 'USA', 2: 'Europe', 3: 'Japan'})
dataset = pd.get_dummies(dataset, columns=['Origin'], prefix='', prefix_sep='')
dataset.tail()
डेटा को प्रशिक्षण और परीक्षण सेट में विभाजित करें
अब, डेटासेट को एक प्रशिक्षण सेट और एक परीक्षण सेट में विभाजित करें। आप अपने मॉडलों के अंतिम मूल्यांकन में परीक्षण सेट का उपयोग करेंगे।
train_dataset = dataset.sample(frac=0.8, random_state=0)
test_dataset = dataset.drop(train_dataset.index)
डेटा का निरीक्षण करें
प्रशिक्षण सेट से कुछ जोड़े स्तंभों के संयुक्त वितरण की समीक्षा करें।
शीर्ष पंक्ति से पता चलता है कि ईंधन दक्षता (एमपीजी) अन्य सभी मापदंडों का एक कार्य है। अन्य पंक्तियाँ इंगित करती हैं कि वे एक दूसरे के कार्य हैं।
sns.pairplot(train_dataset[['MPG', 'Cylinders', 'Displacement', 'Weight']], diag_kind='kde')
<seaborn.axisgrid.PairGrid at 0x7f6bfdae9850>

आइए समग्र आंकड़ों की भी जांच करें। ध्यान दें कि कैसे प्रत्येक सुविधा एक बहुत अलग श्रेणी को कवर करती है:
train_dataset.describe().transpose()
लेबल से सुविधाओं को विभाजित करें
लक्ष्य मान—“लेबल”—को सुविधाओं से अलग करें। यह लेबल वह मान है जिसकी भविष्यवाणी करने के लिए आप मॉडल को प्रशिक्षित करेंगे।
train_features = train_dataset.copy()
test_features = test_dataset.copy()
train_labels = train_features.pop('MPG')
test_labels = test_features.pop('MPG')
मानकीकरण
आंकड़ों की तालिका में यह देखना आसान है कि प्रत्येक विशेषता की श्रेणियां कितनी भिन्न हैं:
train_dataset.describe().transpose()[['mean', 'std']]
विभिन्न पैमानों और श्रेणियों का उपयोग करने वाली सुविधाओं को सामान्य बनाना एक अच्छा अभ्यास है।
एक कारण यह महत्वपूर्ण है क्योंकि सुविधाओं को मॉडल भार से गुणा किया जाता है। तो, आउटपुट के पैमाने और ग्रेडिएंट के पैमाने इनपुट के पैमाने से प्रभावित होते हैं।
हालांकि एक मॉडल सुविधा सामान्यीकरण के बिना अभिसरण हो सकता है, सामान्यीकरण प्रशिक्षण को और अधिक स्थिर बनाता है।
सामान्यीकरण परत
tf.keras.layers.Normalization आपके मॉडल में फीचर नॉर्मलाइजेशन जोड़ने का एक साफ और आसान तरीका है।
परत बनाने के लिए पहला कदम है:
normalizer = tf.keras.layers.Normalization(axis=-1)
फिर, प्रीप्रोसेसिंग परत की स्थिति को Normalization.adapt को कॉल करके डेटा में फ़िट करें:
normalizer.adapt(np.array(train_features))
माध्य और विचरण की गणना करें, और उन्हें परत में संग्रहीत करें:
print(normalizer.mean.numpy())
[[ 5.478 195.318 104.869 2990.252 15.559 75.898 0.178 0.197
0.624]]
जब परत को बुलाया जाता है, तो यह इनपुट डेटा लौटाता है, प्रत्येक सुविधा स्वतंत्र रूप से सामान्यीकृत होती है:
first = np.array(train_features[:1])
with np.printoptions(precision=2, suppress=True):
print('First example:', first)
print()
print('Normalized:', normalizer(first).numpy())
First example: [[ 4. 90. 75. 2125. 14.5 74. 0. 0. 1. ]] Normalized: [[-0.87 -1.01 -0.79 -1.03 -0.38 -0.52 -0.47 -0.5 0.78]]
रेखीय प्रतिगमन
एक डीप न्यूरल नेटवर्क मॉडल बनाने से पहले, एक और कई वेरिएबल्स का उपयोग करके लीनियर रिग्रेशन से शुरुआत करें।
एक चर के साथ रैखिक प्रतिगमन
'Horsepower' से 'MPG' भविष्यवाणी करने के लिए एकल-चर रैखिक प्रतिगमन के साथ शुरू करें।
tf.keras के साथ एक मॉडल का प्रशिक्षण आमतौर पर मॉडल आर्किटेक्चर को परिभाषित करके शुरू होता है। एक tf.keras.Sequential मॉडल का उपयोग करें, जो चरणों के अनुक्रम का प्रतिनिधित्व करता है ।
आपके एकल-चर रैखिक प्रतिगमन मॉडल में दो चरण हैं:
-
tf.keras.layers.Normalizationpreprocessing layer का उपयोग करके'Horsepower'इनपुट सुविधाओं को सामान्य करें। - एक रैखिक परत (
tf.keras.layers.Dense) का उपयोग करके 1 आउटपुट उत्पन्न करने के लिए एक रैखिक परिवर्तन (\(y = mx+b\)) लागू करें।
इनपुट की संख्या या तो input_shape तर्क द्वारा सेट की जा सकती है, या स्वचालित रूप से जब मॉडल पहली बार चलाया जाता है।
सबसे पहले, 'Horsepower' सुविधाओं से बना एक NumPy सरणी बनाएं। फिर, tf.keras.layers.Normalization को तुरंत चालू करें और इसकी स्थिति को horsepower डेटा में फिट करें:
horsepower = np.array(train_features['Horsepower'])
horsepower_normalizer = layers.Normalization(input_shape=[1,], axis=None)
horsepower_normalizer.adapt(horsepower)
केरस अनुक्रमिक मॉडल बनाएँ:
horsepower_model = tf.keras.Sequential([
horsepower_normalizer,
layers.Dense(units=1)
])
horsepower_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense (Dense) (None, 1) 2
=================================================================
Total params: 5
Trainable params: 2
Non-trainable params: 3
_________________________________________________________________
यह मॉडल 'Horsepower' से 'MPG' की भविष्यवाणी करेगा।
अप्रशिक्षित मॉडल को पहले 10 'अश्वशक्ति' मूल्यों पर चलाएँ। आउटपुट अच्छा नहीं होगा, लेकिन ध्यान दें कि इसका अपेक्षित आकार (10, 1) :
horsepower_model.predict(horsepower[:10])
array([[-1.186],
[-0.67 ],
[ 2.189],
[-1.662],
[-1.504],
[-0.59 ],
[-1.782],
[-1.504],
[-0.392],
[-0.67 ]], dtype=float32)
मॉडल बनने के बाद, Model.compile पद्धति का उपयोग करके प्रशिक्षण प्रक्रिया को कॉन्फ़िगर करें। संकलन करने के लिए सबसे महत्वपूर्ण तर्क loss और optimizer हैं, क्योंकि ये परिभाषित करते हैं कि क्या अनुकूलित किया जाएगा ( mean_absolute_error ) और कैसे ( tf.keras.optimizers.Adam का उपयोग करके)।
horsepower_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
100 युगों के प्रशिक्षण को निष्पादित करने के लिए Model.fit का उपयोग करें:
%%time
history = horsepower_model.fit(
train_features['Horsepower'],
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 4.79 s, sys: 797 ms, total: 5.59 s Wall time: 3.8 s
history वस्तु में संग्रहीत आँकड़ों का उपयोग करके मॉडल की प्रशिक्षण प्रगति की कल्पना करें:
hist = pd.DataFrame(history.history)
hist['epoch'] = history.epoch
hist.tail()
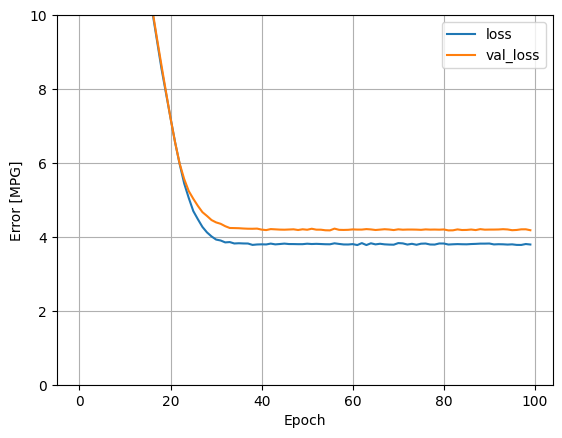
def plot_loss(history):
plt.plot(history.history['loss'], label='loss')
plt.plot(history.history['val_loss'], label='val_loss')
plt.ylim([0, 10])
plt.xlabel('Epoch')
plt.ylabel('Error [MPG]')
plt.legend()
plt.grid(True)
plot_loss(history)
बाद के लिए परीक्षण सेट पर परिणाम एकत्र करें:
test_results = {}
test_results['horsepower_model'] = horsepower_model.evaluate(
test_features['Horsepower'],
test_labels, verbose=0)
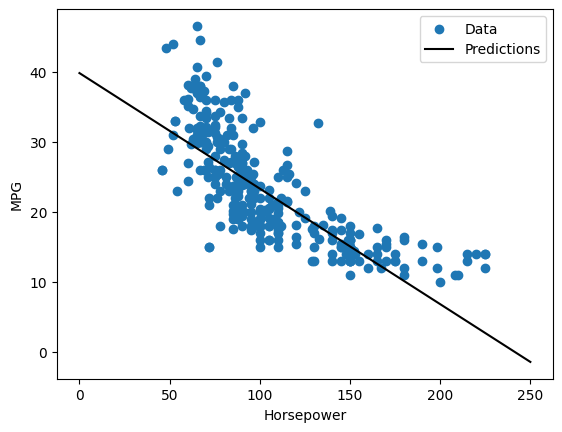
चूंकि यह एक एकल चर प्रतिगमन है, इसलिए मॉडल की भविष्यवाणियों को इनपुट के एक फ़ंक्शन के रूप में देखना आसान है:
x = tf.linspace(0.0, 250, 251)
y = horsepower_model.predict(x)
def plot_horsepower(x, y):
plt.scatter(train_features['Horsepower'], train_labels, label='Data')
plt.plot(x, y, color='k', label='Predictions')
plt.xlabel('Horsepower')
plt.ylabel('MPG')
plt.legend()
plot_horsepower(x, y)
एकाधिक इनपुट के साथ रैखिक प्रतिगमन
आप एकाधिक इनपुट के आधार पर पूर्वानुमान लगाने के लिए लगभग समान सेटअप का उपयोग कर सकते हैं। यह मॉडल अभी भी वही करता है \(y = mx+b\) सिवाय इसके कि \(m\) एक मैट्रिक्स है और \(b\) एक वेक्टर है।
पहली परत normalizer ( tf.keras.layers.Normalization(axis=-1) ) के साथ फिर से दो-चरणीय केरस अनुक्रमिक मॉडल बनाएं, जिसे आपने पहले परिभाषित किया था और पूरे डेटासेट के लिए अनुकूलित किया था:
linear_model = tf.keras.Sequential([
normalizer,
layers.Dense(units=1)
])
जब आप इनपुट के बैच पर Model.predict को कॉल करते हैं, तो यह प्रत्येक उदाहरण के लिए units=1 आउटपुट का उत्पादन करता है:
linear_model.predict(train_features[:10])
array([[ 0.441],
[ 1.522],
[ 0.188],
[ 1.169],
[ 0.058],
[ 0.965],
[ 0.034],
[-0.674],
[ 0.437],
[-0.37 ]], dtype=float32)
जब आप मॉडल को कॉल करते हैं, तो इसका वजन मैट्रिक्स बनाया जाएगा-जांचें कि kernel वजन ( \(m\) में \(y=mx+b\)) का आकार (9, 1) :
linear_model.layers[1].kernel
<tf.Variable 'dense_1/kernel:0' shape=(9, 1) dtype=float32, numpy=
array([[-0.702],
[ 0.307],
[ 0.114],
[ 0.233],
[ 0.244],
[ 0.322],
[-0.725],
[-0.151],
[ 0.407]], dtype=float32)>
मॉडल को Model.compile के साथ कॉन्फ़िगर करें और 100 युगों के लिए Model.fit के साथ प्रशिक्षित करें:
linear_model.compile(
optimizer=tf.optimizers.Adam(learning_rate=0.1),
loss='mean_absolute_error')
%%time
history = linear_model.fit(
train_features,
train_labels,
epochs=100,
# Suppress logging.
verbose=0,
# Calculate validation results on 20% of the training data.
validation_split = 0.2)
CPU times: user 4.89 s, sys: 740 ms, total: 5.63 s Wall time: 3.75 s
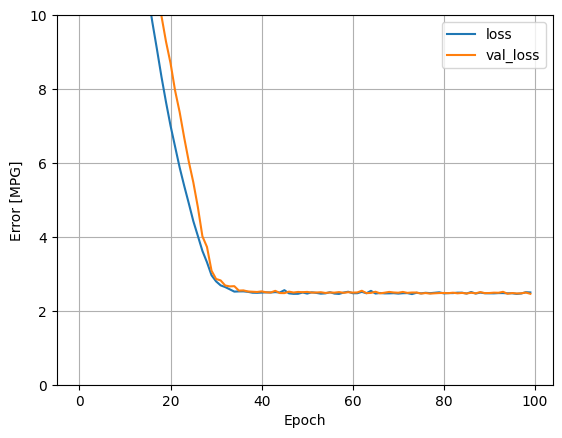
इस रिग्रेशन मॉडल में सभी इनपुट का उपयोग करने से horsepower_model की तुलना में बहुत कम प्रशिक्षण और सत्यापन त्रुटि प्राप्त होती है, जिसमें एक इनपुट था:
plot_loss(history)
बाद के लिए परीक्षण सेट पर परिणाम एकत्र करें:
test_results['linear_model'] = linear_model.evaluate(
test_features, test_labels, verbose=0)
एक गहरे तंत्रिका नेटवर्क (डीएनएन) के साथ प्रतिगमन
पिछले भाग में, आपने सिंगल और मल्टीपल इनपुट के लिए दो लीनियर मॉडल लागू किए थे।
यहां, आप सिंगल-इनपुट और मल्टीपल-इनपुट डीएनएन मॉडल लागू करेंगे।
कोड मूल रूप से समान है सिवाय इसके कि मॉडल को कुछ "छिपी हुई" गैर-रेखीय परतों को शामिल करने के लिए विस्तारित किया गया है। यहां "हिडन" नाम का अर्थ सीधे इनपुट या आउटपुट से जुड़ा नहीं है।
इन मॉडलों में रैखिक मॉडल की तुलना में कुछ और परतें होंगी:
- सामान्यीकरण परत, पहले की तरह (सिंगल-इनपुट मॉडल के लिए
horsepower_normalizerके साथ और मल्टीपल-इनपुट मॉडल के लिएnormalizerके साथ)। -
relu(Dense) सक्रियण फ़ंक्शन nonlinearity के साथ दो छिपी हुई, गैर-रैखिक, घनी परतें। - एक रैखिक
Denseएकल-आउटपुट परत।
दोनों मॉडल समान प्रशिक्षण प्रक्रिया का उपयोग करेंगे, इसलिए compile विधि को नीचे दिए गए build_and_compile_model फ़ंक्शन में शामिल किया गया है।
def build_and_compile_model(norm):
model = keras.Sequential([
norm,
layers.Dense(64, activation='relu'),
layers.Dense(64, activation='relu'),
layers.Dense(1)
])
model.compile(loss='mean_absolute_error',
optimizer=tf.keras.optimizers.Adam(0.001))
return model
एक डीएनएन और एक इनपुट का उपयोग कर रिग्रेशन
इनपुट के रूप में केवल 'Horsepower' और सामान्यीकरण परत के रूप में horsepower_normalizer (पहले परिभाषित) के साथ एक डीएनएन मॉडल बनाएं:
dnn_horsepower_model = build_and_compile_model(horsepower_normalizer)
इस मॉडल में रैखिक मॉडल की तुलना में काफी अधिक प्रशिक्षित पैरामीटर हैं:
dnn_horsepower_model.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization_1 (Normalizat (None, 1) 3
ion)
dense_2 (Dense) (None, 64) 128
dense_3 (Dense) (None, 64) 4160
dense_4 (Dense) (None, 1) 65
=================================================================
Total params: 4,356
Trainable params: 4,353
Non-trainable params: 3
_________________________________________________________________
Model.fit के साथ मॉडल को प्रशिक्षित करें:
%%time
history = dnn_horsepower_model.fit(
train_features['Horsepower'],
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 5.07 s, sys: 691 ms, total: 5.76 s Wall time: 3.92 s
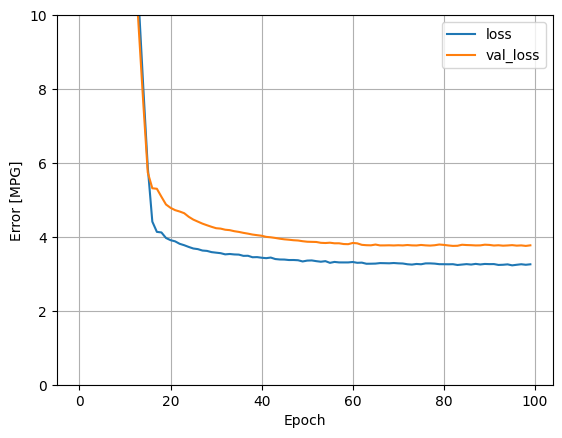
यह मॉडल लीनियर सिंगल-इनपुट horsepower_model से थोड़ा बेहतर करता है:
plot_loss(history)
यदि आप भविष्यवाणियों को 'Horsepower' के एक कार्य के रूप में प्लॉट करते हैं, तो आपको ध्यान देना चाहिए कि यह मॉडल छिपी हुई परतों द्वारा प्रदान की गई गैर-रैखिकता का लाभ कैसे उठाता है:
x = tf.linspace(0.0, 250, 251)
y = dnn_horsepower_model.predict(x)
plot_horsepower(x, y)
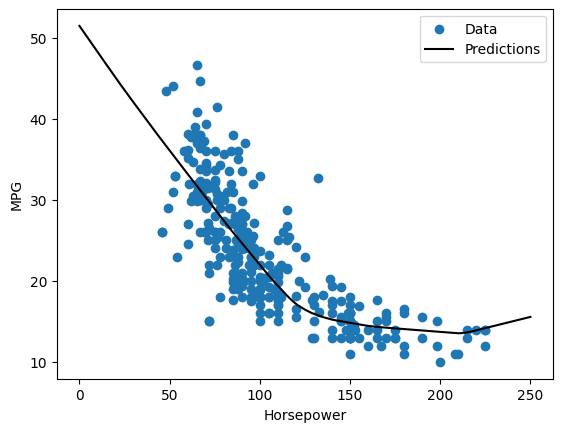
बाद के लिए परीक्षण सेट पर परिणाम एकत्र करें:
test_results['dnn_horsepower_model'] = dnn_horsepower_model.evaluate(
test_features['Horsepower'], test_labels,
verbose=0)
एक डीएनएन और एकाधिक इनपुट का उपयोग कर रिग्रेशन
सभी इनपुट का उपयोग करके पिछली प्रक्रिया को दोहराएं। सत्यापन डेटासेट पर मॉडल के प्रदर्शन में थोड़ा सुधार होता है।
dnn_model = build_and_compile_model(normalizer)
dnn_model.summary()
Model: "sequential_3"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
normalization (Normalizatio (None, 9) 19
n)
dense_5 (Dense) (None, 64) 640
dense_6 (Dense) (None, 64) 4160
dense_7 (Dense) (None, 1) 65
=================================================================
Total params: 4,884
Trainable params: 4,865
Non-trainable params: 19
_________________________________________________________________
%%time
history = dnn_model.fit(
train_features,
train_labels,
validation_split=0.2,
verbose=0, epochs=100)
CPU times: user 5.08 s, sys: 725 ms, total: 5.8 s Wall time: 3.94 s
plot_loss(history)
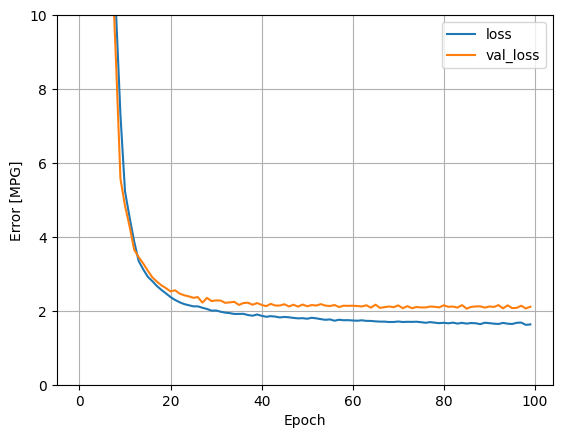
परीक्षण सेट पर परिणाम एकत्र करें:
test_results['dnn_model'] = dnn_model.evaluate(test_features, test_labels, verbose=0)
प्रदर्शन
चूंकि सभी मॉडलों को प्रशिक्षित किया गया है, आप उनके परीक्षण सेट के प्रदर्शन की समीक्षा कर सकते हैं:
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
ये परिणाम प्रशिक्षण के दौरान देखी गई सत्यापन त्रुटि से मेल खाते हैं।
अंदाजा लगाओ
अब आप Keras Model.predict का उपयोग करके परीक्षण सेट पर dnn_model के साथ भविष्यवाणियां कर सकते हैं और नुकसान की समीक्षा कर सकते हैं:
test_predictions = dnn_model.predict(test_features).flatten()
a = plt.axes(aspect='equal')
plt.scatter(test_labels, test_predictions)
plt.xlabel('True Values [MPG]')
plt.ylabel('Predictions [MPG]')
lims = [0, 50]
plt.xlim(lims)
plt.ylim(lims)
_ = plt.plot(lims, lims)

ऐसा प्रतीत होता है कि मॉडल यथोचित भविष्यवाणी करता है।
अब, त्रुटि वितरण की जाँच करें:
error = test_predictions - test_labels
plt.hist(error, bins=25)
plt.xlabel('Prediction Error [MPG]')
_ = plt.ylabel('Count')

यदि आप मॉडल से खुश हैं, तो इसे Model.save के साथ बाद में उपयोग के लिए सहेजें:
dnn_model.save('dnn_model')
2022-01-26 07:26:13.372245: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. INFO:tensorflow:Assets written to: dnn_model/assets
यदि आप मॉडल को पुनः लोड करते हैं, तो यह समान आउटपुट देता है:
reloaded = tf.keras.models.load_model('dnn_model')
test_results['reloaded'] = reloaded.evaluate(
test_features, test_labels, verbose=0)
pd.DataFrame(test_results, index=['Mean absolute error [MPG]']).T
निष्कर्ष
इस नोटबुक ने प्रतिगमन समस्या से निपटने के लिए कुछ तकनीकों का परिचय दिया। यहां कुछ और युक्तियां दी गई हैं जो मदद कर सकती हैं:
- माध्य चुकता त्रुटि (MSE) (
tf.losses.MeanSquaredError) और माध्य निरपेक्ष त्रुटि (MAE) (tf.losses.MeanAbsoluteError) प्रतिगमन समस्याओं के लिए उपयोग किए जाने वाले सामान्य हानि कार्य हैं। एमएई आउटलेर्स के प्रति कम संवेदनशील है। वर्गीकरण समस्याओं के लिए विभिन्न हानि कार्यों का उपयोग किया जाता है। - इसी तरह, प्रतिगमन के लिए उपयोग किए जाने वाले मूल्यांकन मेट्रिक्स वर्गीकरण से भिन्न होते हैं।
- जब संख्यात्मक इनपुट डेटा सुविधाओं में अलग-अलग श्रेणियों के मान होते हैं, तो प्रत्येक सुविधा को स्वतंत्र रूप से समान श्रेणी में स्केल किया जाना चाहिए।
- DNN मॉडल के लिए ओवरफिटिंग एक आम समस्या है, हालांकि यह इस ट्यूटोरियल के लिए कोई समस्या नहीं थी। इसके बारे में अधिक सहायता के लिए ओवरफिट और अंडरफिट ट्यूटोरियल पर जाएं।
# MIT License
#
# Copyright (c) 2017 François Chollet
#
# Permission is hereby granted, free of charge, to any person obtaining a
# copy of this software and associated documentation files (the "Software"),
# to deal in the Software without restriction, including without limitation
# the rights to use, copy, modify, merge, publish, distribute, sublicense,
# and/or sell copies of the Software, and to permit persons to whom the
# Software is furnished to do so, subject to the following conditions:
#
# The above copyright notice and this permission notice shall be included in
# all copies or substantial portions of the Software.
#
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL
# THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER
# DEALINGS IN THE SOFTWARE.