
| | |  GitHub'da görüntüle GitHub'da görüntüle | |
Bu CoLab kullanmanın bir tanıtımdır Tensorflow Hub İngilizce olmayan / yerel dillerde metin sınıflandırma için. Burada seçim Bangla yerel dil olarak ve biz 5 kategoride Bangla haber makalelerini sınıflandırmak bir çok sınıflı sınıflandırma görevi çözmek için kelime katıştırmalarını pretrained kullanın. Bangla için pretrained kalıplamaların geliyor Fasttext 157 dilde yayımlanan pretrained kelime vektörler ile Facebook tarafından bir kütüphanedir.
Önce bir metin gömme modülüne kelime katıştırmalarını dönüştürmek için TF-Hub pretrained katıştırma ihracatçısı kullanacağız ve ardından aldığı bir sınıflandırıcı yetiştirmek modülü kullanmak tf.keras , Tensorflow en yüksek düzeyde kullanıcı dostu API derin öğrenme modellerini oluşturmak için. Burada fastText yerleştirmelerini kullanıyor olsak bile, diğer görevlerden önceden eğitilmiş diğer yerleştirmeleri dışa aktarmak ve Tensorflow hub ile hızlı bir şekilde sonuç almak mümkündür.
Kurmak
# https://github.com/pypa/setuptools/issues/1694#issuecomment-466010982pip install gdown --no-use-pep517
sudo apt-get install -y unzip
Reading package lists... Building dependency tree... Reading state information... unzip is already the newest version (6.0-21ubuntu1.1). The following packages were automatically installed and are no longer required: linux-gcp-5.4-headers-5.4.0-1040 linux-gcp-5.4-headers-5.4.0-1043 linux-gcp-5.4-headers-5.4.0-1044 linux-gcp-5.4-headers-5.4.0-1049 linux-headers-5.4.0-1049-gcp linux-image-5.4.0-1049-gcp linux-modules-5.4.0-1049-gcp linux-modules-extra-5.4.0-1049-gcp Use 'sudo apt autoremove' to remove them. 0 upgraded, 0 newly installed, 0 to remove and 143 not upgraded.
import os
import tensorflow as tf
import tensorflow_hub as hub
import gdown
import numpy as np
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
import seaborn as sns
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
veri kümesi
Biz kullanacağız Bard ekonomi, devlet, uluslararası, spor ve eğlence: Farklı Bangla haber portallarından toplanan ve 5 kategori ile etiketlenmiş etrafında 376.226 makaleleri vardır (Bangla Madde Veri seti). Bu (Google Drive, dosyayı indirmeye bit.ly/BARD_DATASET ) linkinden bahsediyor bu GitHub depo.
gdown.download(
url='https://drive.google.com/uc?id=1Ag0jd21oRwJhVFIBohmX_ogeojVtapLy',
output='bard.zip',
quiet=True
)
'bard.zip'
unzip -qo bard.zip
Önceden eğitilmiş kelime vektörlerini TF-Hub modülüne aktarın
TF-Hub TF-göbek metin katıştırma modülleri kelime katıştırmalarını dönüştürmek için bazı yararlı komut dosyaları sağlar burada . Bangla'daki veya başka bir dil için modül yapmak için, biz sadece gömme sözcüğü indirmek zorunda .txt veya .vec aynı dizine export_v2.py ve komut dosyasını çalıştırın.
İhracatçı gömme vektörleri okur ve bir Tensorflow bunu ihraç SavedModel . SavedModel, ağırlıkları ve grafiği içeren eksiksiz bir TensorFlow programı içerir. TF-Hub bir şekilde SavedModel yükleyebilirsiniz modülü biz metin sınıflandırma için model oluşturmak için kullanacaktır. Kullandığımız yana tf.keras model oluşturmak için, kullanacağımız hub.KerasLayer bir Keras bir tabaka olarak kullanım için bir TF-Hub modülü için bir sargıyı içerir.
İlk olarak TF-Hub bizim kelime Fasttext gelen katıştırmalarını ve gömme ihracatçısı alacak repo .
curl -O https://dl.fbaipublicfiles.com/fasttext/vectors-crawl/cc.bn.300.vec.gzcurl -O https://raw.githubusercontent.com/tensorflow/hub/master/examples/text_embeddings_v2/export_v2.pygunzip -qf cc.bn.300.vec.gz --k
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 840M 100 840M 0 0 11.6M 0 0:01:12 0:01:12 --:--:-- 12.0M
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 7469 100 7469 0 0 19053 0 --:--:-- --:--:-- --:--:-- 19005
Ardından, gömme dosyamızdaki ihracatçı betiğini çalıştıracağız. fastText yerleştirmeleri bir başlık satırına sahip olduğundan ve oldukça büyük olduğundan (bir modüle dönüştürdükten sonra Bangla için yaklaşık 3,3 GB), ilk satırı yok sayar ve metin yerleştirme modülüne yalnızca ilk 100.000 jetonu dışa aktarırız.
python export_v2.py --embedding_file=cc.bn.300.vec --export_path=text_module --num_lines_to_ignore=1 --num_lines_to_use=100000
INFO:tensorflow:Assets written to: text_module/assets I1105 11:55:29.817717 140238757988160 builder_impl.py:784] Assets written to: text_module/assets
module_path = "text_module"
embedding_layer = hub.KerasLayer(module_path, trainable=False)
Metin gömme modülü, girdi olarak bir 1D dizgi tensöründe bir dizi cümle alır ve cümlelere karşılık gelen gömme şekil vektörlerini (batch_size, embedding_dim) verir. Boşluklara bölerek girişi önceden işler. Kelime kalıplamaların ile cümle tespitlerinin birleştirilerek sqrtn birleştirici (Bkz buraya ). Gösterim için, girdi olarak bir Bangla kelime listesi iletiyoruz ve ilgili gömme vektörlerini alıyoruz.
embedding_layer(['বাস', 'বসবাস', 'ট্রেন', 'যাত্রী', 'ট্রাক'])
<tf.Tensor: shape=(5, 300), dtype=float64, numpy=
array([[ 0.0462, -0.0355, 0.0129, ..., 0.0025, -0.0966, 0.0216],
[-0.0631, -0.0051, 0.085 , ..., 0.0249, -0.0149, 0.0203],
[ 0.1371, -0.069 , -0.1176, ..., 0.029 , 0.0508, -0.026 ],
[ 0.0532, -0.0465, -0.0504, ..., 0.02 , -0.0023, 0.0011],
[ 0.0908, -0.0404, -0.0536, ..., -0.0275, 0.0528, 0.0253]])>
Tensorflow Veri Kümesine Dönüştür
Veri kümesi yerine bellekte tüm veri kümesini yükleme gerçekten büyük olduğu için kullandığımız gruplar halinde çalışma zamanında örnekleri elde etmek için bir jeneratör kullanacak Tensorflow Veri kümesi fonksiyonları. Veri kümesi de çok dengesizdir, bu nedenle üreteci kullanmadan önce veri kümesini karıştıracağız.
dir_names = ['economy', 'sports', 'entertainment', 'state', 'international']
file_paths = []
labels = []
for i, dir in enumerate(dir_names):
file_names = ["/".join([dir, name]) for name in os.listdir(dir)]
file_paths += file_names
labels += [i] * len(os.listdir(dir))
np.random.seed(42)
permutation = np.random.permutation(len(file_paths))
file_paths = np.array(file_paths)[permutation]
labels = np.array(labels)[permutation]
Karıştırdıktan sonra eğitim ve doğrulama örneklerinde etiketlerin dağılımını kontrol edebiliriz.
train_frac = 0.8
train_size = int(len(file_paths) * train_frac)
# plot training vs validation distribution
plt.subplot(1, 2, 1)
plt.hist(labels[0:train_size])
plt.title("Train labels")
plt.subplot(1, 2, 2)
plt.hist(labels[train_size:])
plt.title("Validation labels")
plt.tight_layout()
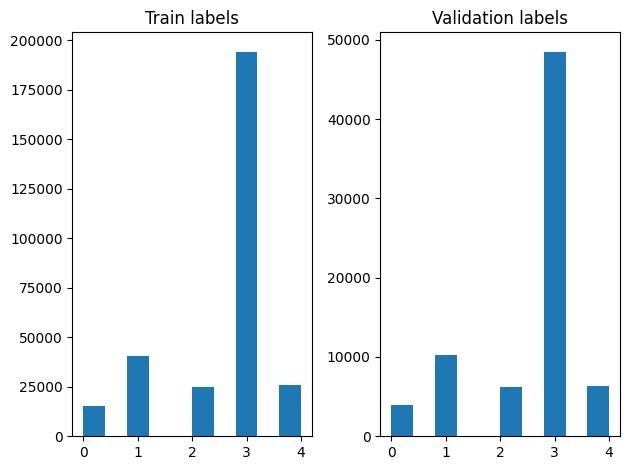
Bir oluşturmak için Dataset bir jeneratör kullanarak, öncelikle bir jeneratör makalelerin her okur fonksiyon yazmak file_paths her adımda etiket diziden ve etiketler ve verimi bir eğitim örneği. Biz bu jeneratör işlevi geçmesi tf.data.Dataset.from_generator yöntemi ve çıkış türlerini belirtir. Her eğitim örneğin bir maddesi içeren bir başlık olur tf.string veri tipi ve bir sıcak kodlanmış etiket. Biz kullanarak 80-20 bir tren doğrulama bölünmüş veri kümesi bölmek tf.data.Dataset.skip ve tf.data.Dataset.take yöntemleri.
def load_file(path, label):
return tf.io.read_file(path), label
def make_datasets(train_size):
batch_size = 256
train_files = file_paths[:train_size]
train_labels = labels[:train_size]
train_ds = tf.data.Dataset.from_tensor_slices((train_files, train_labels))
train_ds = train_ds.map(load_file).shuffle(5000)
train_ds = train_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
test_files = file_paths[train_size:]
test_labels = labels[train_size:]
test_ds = tf.data.Dataset.from_tensor_slices((test_files, test_labels))
test_ds = test_ds.map(load_file)
test_ds = test_ds.batch(batch_size).prefetch(tf.data.AUTOTUNE)
return train_ds, test_ds
train_data, validation_data = make_datasets(train_size)
Model Eğitimi ve Değerlendirmesi
Daha önce keras başka katman olarak kullanmak için modül etrafında sarıcı ilave beri, küçük oluşturabilir ardışık katmanların doğrusal yığını modeli. Biz bizim metin gömme modülü ekleyebilir model.add tıpkı diğer katman gibi. Modeli, kayıp ve optimize ediciyi belirterek derliyoruz ve 10 epoch için eğitiyoruz. tf.keras biz modeli eğitim için uygun yönteme bir Veri kümesi örneğini geçirebilmeleri için API, girdi olarak Tensorflow Veri Kümeleri işleyebilir. Jeneratörü fonksiyonunu kullanarak beri, tf.data , örneklerini oluşturan bunları dozajları ve modeli 'ne yedirilmeleri idare edecektir.
modeli
def create_model():
model = tf.keras.Sequential([
tf.keras.layers.Input(shape=[], dtype=tf.string),
embedding_layer,
tf.keras.layers.Dense(64, activation="relu"),
tf.keras.layers.Dense(16, activation="relu"),
tf.keras.layers.Dense(5),
])
model.compile(loss=tf.losses.SparseCategoricalCrossentropy(from_logits=True),
optimizer="adam", metrics=['accuracy'])
return model
model = create_model()
# Create earlystopping callback
early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor='val_loss', min_delta=0, patience=3)
Eğitim
history = model.fit(train_data,
validation_data=validation_data,
epochs=5,
callbacks=[early_stopping_callback])
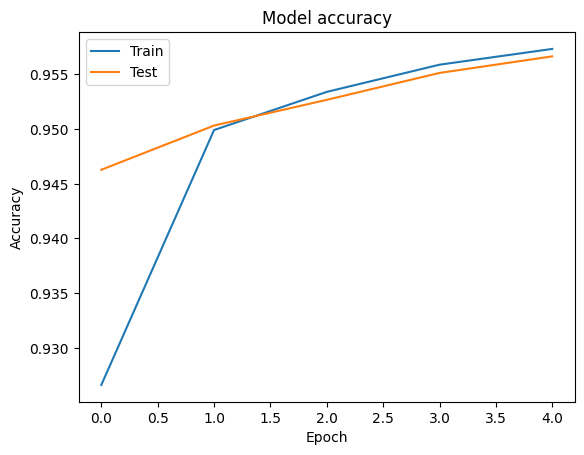
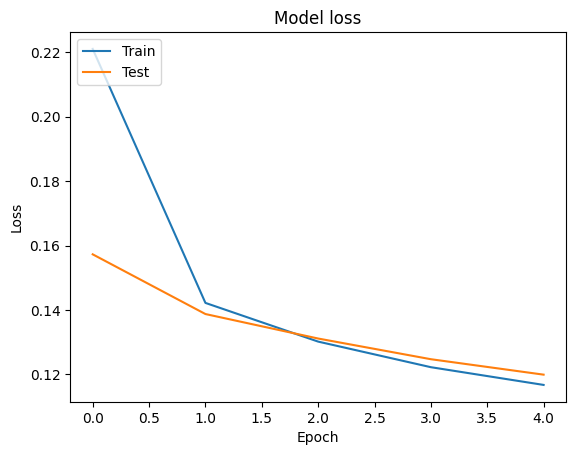
Epoch 1/5 1176/1176 [==============================] - 34s 28ms/step - loss: 0.2181 - accuracy: 0.9279 - val_loss: 0.1580 - val_accuracy: 0.9449 Epoch 2/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1411 - accuracy: 0.9505 - val_loss: 0.1411 - val_accuracy: 0.9503 Epoch 3/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1307 - accuracy: 0.9534 - val_loss: 0.1359 - val_accuracy: 0.9524 Epoch 4/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1248 - accuracy: 0.9555 - val_loss: 0.1318 - val_accuracy: 0.9527 Epoch 5/5 1176/1176 [==============================] - 32s 27ms/step - loss: 0.1196 - accuracy: 0.9567 - val_loss: 0.1247 - val_accuracy: 0.9555
Değerlendirme
Biz kullanılarak eğitim ve doğrulama verileri için doğru ve kayıp eğrilerini görselleştirmek tf.keras.callbacks.History tarafından döndürülen bir nesne tf.keras.Model.fit her dönem için kaybı ve doğruluk değeri içeren bir yöntem.
# Plot training & validation accuracy values
plt.plot(history.history['accuracy'])
plt.plot(history.history['val_accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
# Plot training & validation loss values
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
Tahmin
Doğrulama verileri için tahminleri alabilir ve 5 sınıfın her biri için modelin performansını görmek için karışıklık matrisini kontrol edebiliriz. Çünkü tf.keras.Model.predict yöntem, her sınıf için olasılıklar için bir nd dizi döner, bu kullanarak sınıf etiket dönüştürülebilir np.argmax .
y_pred = model.predict(validation_data)
y_pred = np.argmax(y_pred, axis=1)
samples = file_paths[0:3]
for i, sample in enumerate(samples):
f = open(sample)
text = f.read()
print(text[0:100])
print("True Class: ", sample.split("/")[0])
print("Predicted Class: ", dir_names[y_pred[i]])
f.close()
রবিন উইলিয়ামস তাঁর হ্যাপি ফিট ছবিতে মজা করে বলেছিলেন, ‘আমি শুনতে পাচ্ছি, মানুষ কিছু একটা চাইছে...সে True Class: entertainment Predicted Class: state নির্মাণ শেষে ফিতা কেটে মন্ত্রী ভবন উদ্বোধন করেছেন বহু আগেই। তবে এখনো চালু করা যায়নি খাগড়াছড়ি জেল True Class: state Predicted Class: state কমলাপুর বীরশ্রেষ্ঠ মোস্তফা কামাল স্টেডিয়ামে কাল ফকিরেরপুল ইয়ংমেন্স ক্লাব ৩-০ গোলে হারিয়েছে স্বাধ True Class: sports Predicted Class: state
Performansı Karşılaştır
Şimdi gelen doğrulama verileri için doğru etiketleri alabilir labels ve almak için bizim tahminler ile karşılaştırmak classification_report .
y_true = np.array(labels[train_size:])
print(classification_report(y_true, y_pred, target_names=dir_names))
precision recall f1-score support
economy 0.83 0.76 0.79 3897
sports 0.99 0.98 0.98 10204
entertainment 0.90 0.94 0.92 6256
state 0.97 0.97 0.97 48512
international 0.92 0.93 0.93 6377
accuracy 0.96 75246
macro avg 0.92 0.92 0.92 75246
weighted avg 0.96 0.96 0.96 75246
Ayrıca orijinal elde yayınlanan sonuçlarla bizim modelin performansını karşılaştırabilirsiniz kağıt 0.96 hassas hayranlarıyla orijinal yazarlar birçok ön işleme aşamaları böyle, noktalama ve rakam bırakarak en iyi 25 en yoluylaSQLConfigDataSourceilefRequestparametre durdurma sözcükleri ayıklaması gibi veri kümesi üzerinde gerçekleştirilen tarif vardı. Biz görebileceğiniz gibi classification_report , biz de herhangi bir ön işleme olmadan sadece 5 dönemini için eğitim sonrasında 0,96 hassasiyet ve doğruluk elde etmek için yönetmek!
Bizim gömme modülünden Keras tabakası oluştururken Bu örnekte, biz parametre set trainable=False eğitim sırasında güncelleştirilmiş olmayacak gömme ağırlıklarını demektir. Bunu belirlemeyi deneyin True sadece 2 dönemini sonra bu veri kümesini kullanarak etrafında% 97 doğruluk ulaşmak için.