
lớp cuối cùng công khai ParallelDynamicStitch
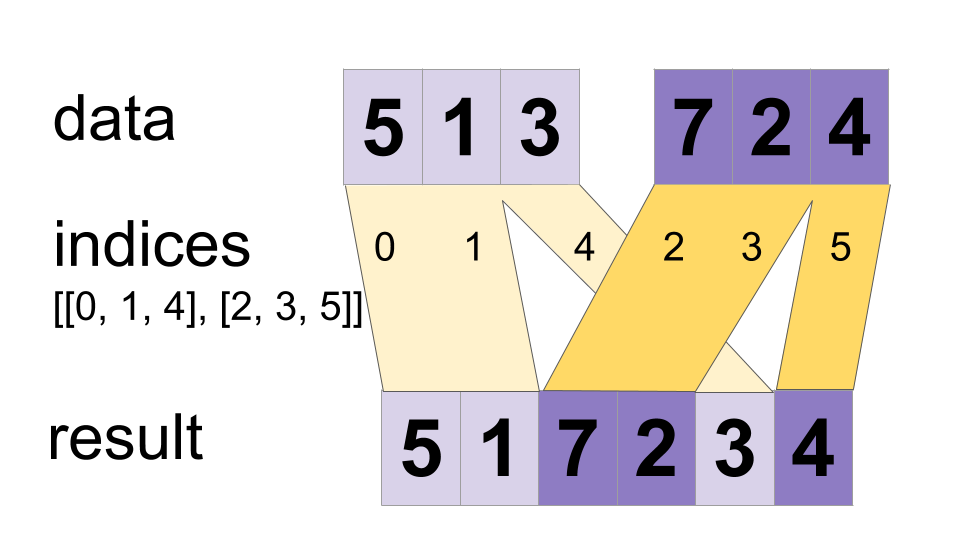
Xen kẽ các giá trị từ tensor `data` thành một tensor duy nhất.
Xây dựng một tensor đã hợp nhất sao cho
merged[indices[m][i, ..., j], ...] = data[m][i, ..., j, ...]
# Scalar indices:
merged[indices[m], ...] = data[m][...]
# Vector indices:
merged[indices[m][i], ...] = data[m][i, ...]
sáp nhập.shape = [max(chỉ số)] + hằng số
Các giá trị có thể được hợp nhất song song, vì vậy nếu một chỉ mục xuất hiện trong cả `indices[m][i]` và `indices[n][j]`, kết quả có thể không hợp lệ. Điều này khác với toán tử DynamicStitch thông thường xác định hành vi trong trường hợp đó.
Ví dụ:
indices[0] = 6
indices[1] = [4, 1]
indices[2] = [[5, 2], [0, 3]]
data[0] = [61, 62]
data[1] = [[41, 42], [11, 12]]
data[2] = [[[51, 52], [21, 22]], [[1, 2], [31, 32]]]
merged = [[1, 2], [11, 12], [21, 22], [31, 32], [41, 42],
[51, 52], [61, 62]]
# Apply function (increments x_i) on elements for which a certain condition
# apply (x_i != -1 in this example).
x=tf.constant([0.1, -1., 5.2, 4.3, -1., 7.4])
condition_mask=tf.not_equal(x,tf.constant(-1.))
partitioned_data = tf.dynamic_partition(
x, tf.cast(condition_mask, tf.int32) , 2)
partitioned_data[1] = partitioned_data[1] + 1.0
condition_indices = tf.dynamic_partition(
tf.range(tf.shape(x)[0]), tf.cast(condition_mask, tf.int32) , 2)
x = tf.dynamic_stitch(condition_indices, partitioned_data)
# Here x=[1.1, -1., 6.2, 5.3, -1, 8.4], the -1. values remain
# unchanged.
Phương pháp công khai
| Đầu ra <T> | asOutput () Trả về phần điều khiển tượng trưng của một tenxơ. |
| tĩnh <T> ParallelDynamicStitch <T> | |
| Đầu ra <T> | đã hợp nhất () |
Phương pháp kế thừa
Phương pháp công khai
Đầu ra công khai <T> asOutput ()
Trả về phần điều khiển tượng trưng của một tenxơ.
Đầu vào của các hoạt động TensorFlow là đầu ra của một hoạt động TensorFlow khác. Phương pháp này được sử dụng để thu được một thẻ điều khiển mang tính biểu tượng đại diện cho việc tính toán đầu vào.
public static ParallelDynamicStitch <T> tạo ( Phạm vi phạm vi, Iterable< Toán hạng <Integer>> chỉ số, Dữ liệu Iterable< Toán hạng <T>>)
Phương thức gốc để tạo một lớp bao bọc một thao tác ParallelDynamicStitch mới.
Thông số
| phạm vi | phạm vi hiện tại |
|---|
Trả lại
- một phiên bản mới của ParallelDynamicStitch